Dynamic 3D Gaze from Afar: Deep Gaze Estimation from Temporal Eye-Head-Body Coordination
Soma Nonaka1, Shohei Nobuhara1,2, and Ko Nishino1 1 Kyoto University 2 JST PRESTO
We introduce a novel method and dataset for 3D gaze estimation of a freely moving person from a distance, typically in surveillance views. Eyes cannot be clearly seen in such cases due to occlusion and lacking resolution. Existing gaze estimation methods suffer or fall back to approximating gaze with head pose as they primarily rely on clear, close-up views of the eyes. Our key idea is to instead leverage the intrinsic gaze, head, and body coordination of people. Our method formulates gaze estimation as Bayesian prediction given temporal estimates of head and body orientations which can be reliably estimated from a far. We model the head and body orientation likelihoods and the conditional prior of gaze direction on those with separate neural networks which are then cascaded to output the 3D gaze direction. We introduce an extensive new dataset that consists of surveillance videos annotated with 3D gaze directions captured in 5 indoor and outdoor scenes. Experimental results on this and other datasets validate the accuracy of our method and demonstrate that gaze can be accurately estimated from a typical surveillance distance even when the person’s face is not visible to the camera.
Dynamic 3D Gaze from Afar: Deep Gaze Estimation from Temporal Eye-Head-Body Coordination
S. Nonaka, S. Nobuhara, and K. Nishino,
in Proc. of Conference on Computer Vision and Pattern Recognition CVPR’22, Jun., 2022.
[ paper ][ supp. pdf ][ supp. video ][ project ][ code/data ]
Supplementary Video
Dynamic 3D Gaze from Afar
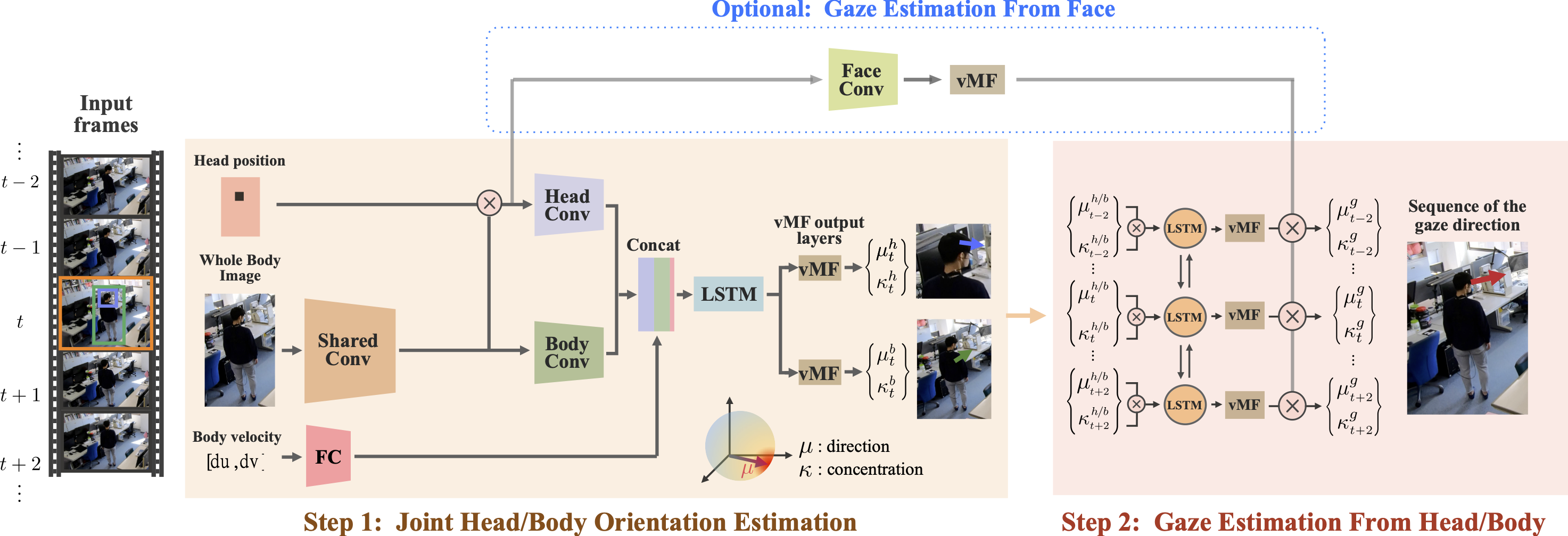
Instead of relying on eye appearance, we estimate gaze direction from head and body orientations which can be robustly estimated from surveillance views by leveraging the angular-temporal dependency of gaze-head-body orientations. The figure shows the overview of our framework. Given a sequence of video frames of a person captured at a distance, we first estimate the head and body orientations by devising a network that uses both the body appearance and 2D trajectory. These orientations are estimated as von Mises-Fisher distributions to canonically represent their uncertainties. These head and body orientation likelihoods are then multiplied with a learned conditional prior of the gaze direction given the head and body orientations that encode their natural temporal coordination. We model this conditional prior with a network that encodes the temporal dependency of gaze direction in each frame on past and future head and body orientations. Optionally, we extend our method to opportunistically leverage the eye appearance when they happen to be visible.
GAze From Afar (GAFA) dataset
We also introduce the GAze From Afar (GAFA) dataset, consisting of surveillance videos of freely moving people with automatically annotated 3D gaze, head, and body orientations. We collected data from 8 subj. × 5 daily scenes × 3-9 cameras that collectively cover a variety of gaze behaviors. In contrast to the previous gaze dataset which only contains close-up images of faces or images of people standing still, our dataset contains large pose variations and occlusions by various environmental factors. Most important, their eyes are mostly not visible as is often the case in surveillance videos. Our dataset is the first publicly available dataset of its kind and can serve as a common platform for advancing 3D gaze estimation in the wild.
Results
To evaluate how well our gaze estimation method works in realistic surveillance videos, we train and test our model with the GAFA dataset. Figure (a) shows the estimated (orange) and true (blue) gaze directions from our model on the GAFA dataset. Our method accurately estimates gaze direction in each environment even when the eyes are completely occluded. We also examined the generalization performance of our model on the MoDiPro dataset (Dias et al., 2019), which contains surveillance videos with manually annotated 2D gaze directions. As shown in figure (b), our model trained on the GAFA dataset shows better generalization performance than previous methods when tested on the MoDiPro dataset.
Our method also works well for real-world videos (from the PoseTrack dataset, Andriluka et al., 2018) of very different scenes from the training data, which demonstrates its generalizability. Please see the supplementary video.