Tracking pedestrians is a vital component of many computer vision applications including surveillance, scene understanding, and behavior analysis. Videos of crowded scenes present significant challenges to tracking due to the large number of pedestrians and the frequent partial occlusions that they produce. The movement of each pedestrian, however, contributes to the overall crowd motion (i.e., the collective motions of the scene’s constituents over the entire video) that exhibits an underlying spatially and temporally varying structured pattern. In this paper, we present a novel Bayesian framework for tracking pedestrians in videos of crowded scenes using a space-time model of the crowd motion. We represent the crowd motion with a collection of hidden Markov models trained on local spatio-temporal motion patterns, i.e., the motion patterns exhibited by pedestrians as they move through local space-time regions of the video. Using this unique representation, we predict the next local spatio-temporal motion pattern a tracked pedestrian will exhibit based on the observed frames of the video. We then use this prediction as a prior for tracking the movement of an individual in videos of extremely crowded scenes. We show that our approach of leveraging the crowd motion enables tracking in videos of complex scenes that present unique difficulty to other approaches.
Tracking Pedestrians using Local Spatio-Temporal Motion Patterns in Extremely Crowded Scenes
L. Kratz and K. Nishino,
in IEEE Trans. on Pattern Analysis and Machine Intelligence, vol. 34, no. 5, pp987-1002, May, 2012.
[ paper ] [ IEEE ] [ video mov/ avi ][ project ]
Tracking with Local Spatio-Temporal Motion Patterns in Extremely Crowded Scenes
L. Kratz and K. Nishino,
in Proc. of IEEE International Conference on Computer Vision and Pattern Recognition CVPR’10, Jun., 2010.
[ paper ][ project ]
Also see the following paper which introduces a better crowd flow model:
Going With the Flow: Pedestrian Efficiency in Crowded Scenes
L. Kratz and K. Nishino,
in Proc. of European Conference on Computer Vision ECCV’12, Part IV, pp558-572, Oct., 2012.
[ paper ][ video mov/avi ]
Overview
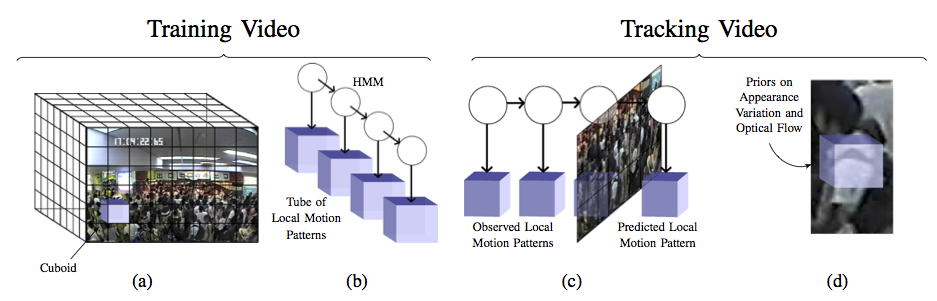
An overview of our model of the crowd motion for tracking in videos of extremely crowded scenes. We divide the video into spatio-temporal sub-volumes, or cuboids, defined by a regular grid (a) and compute the local spatio-temporal motion pattern within each. We then train a hidden Markov model (b) on the local spatio-temporal motion patterns at each spatial location, or tube, of the training video to represent the spatially and temporally varying crowd motion. Using the HMM and previously observed frames of a separate tracking video of the same scene, we predict (c) the local spatio-temporal motion pattern that describes how a target moves through the video. Finally, we use this predicted local spatio-temporal motion pattern to hypothesize a set of priors (d) on the motion and appearance variation of individuals that we wish to track.
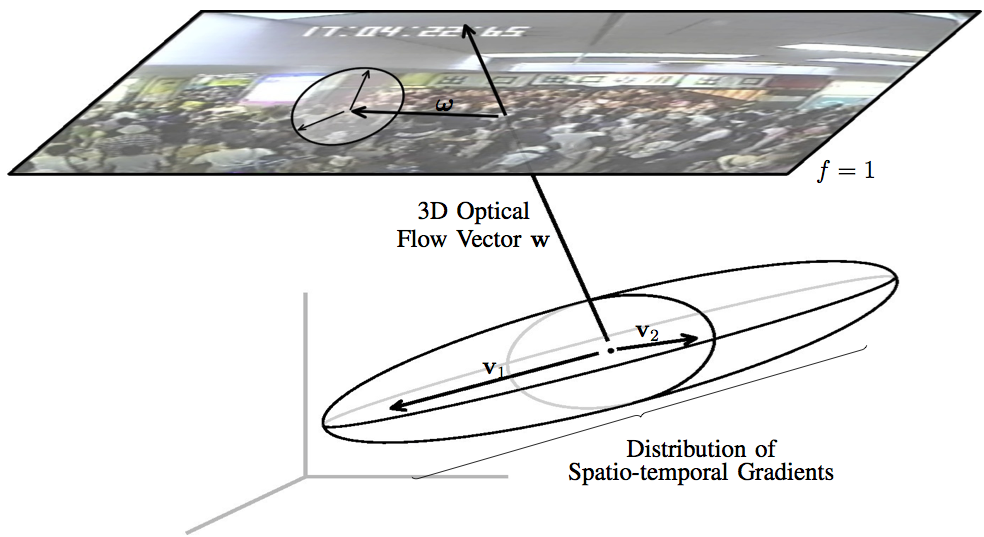
We hypothesize a full distribution of optical flow for the tracked target using the local spatio-temporal motion pattern predicted by the crowd motion. The 3D optical flow w is estimated from the predicted local spatio-temporal motion pattern as the structure tensor’s eigenvector with the smallest eigenvalue. The 2D optical flow is its projection onto the plane f = 1 and represents the predicted movement of the target. We estimate the optical flow’s variance by projecting the other two eigenvectors v1 and v2 onto the same plane, and by scaling them with respect to the eigenvalues.
The direction of the predicted optical flow for the same spatial location in different frames of the sidewalk scene. Our temporally varying model accurately predicts the changing direction of pedestrians as the video progresses.
Results
Please note that unfortunately we are not allowed to show some of the results in the paper in video format.
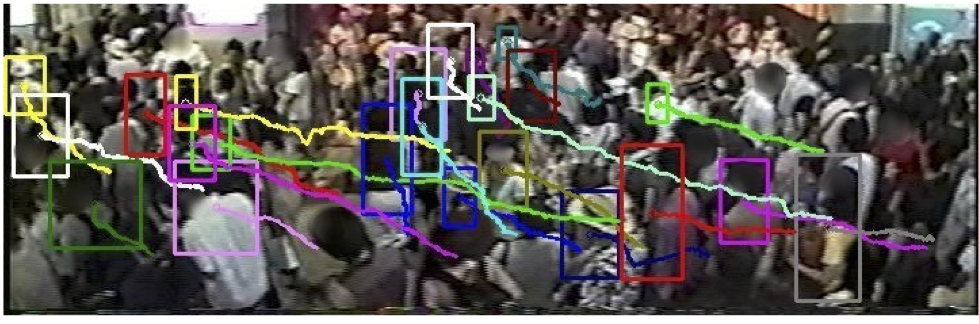
Frames showing our method of tracking pedestrians in videos of the concourse, ticket gate, sidewalk, and intersection scenes, respectively. The faces in the train station scenes have been blurred to conceal identities. The video sequence in each row progresses from left to right, and each curve shows the target’s trajectory up to the current frame.