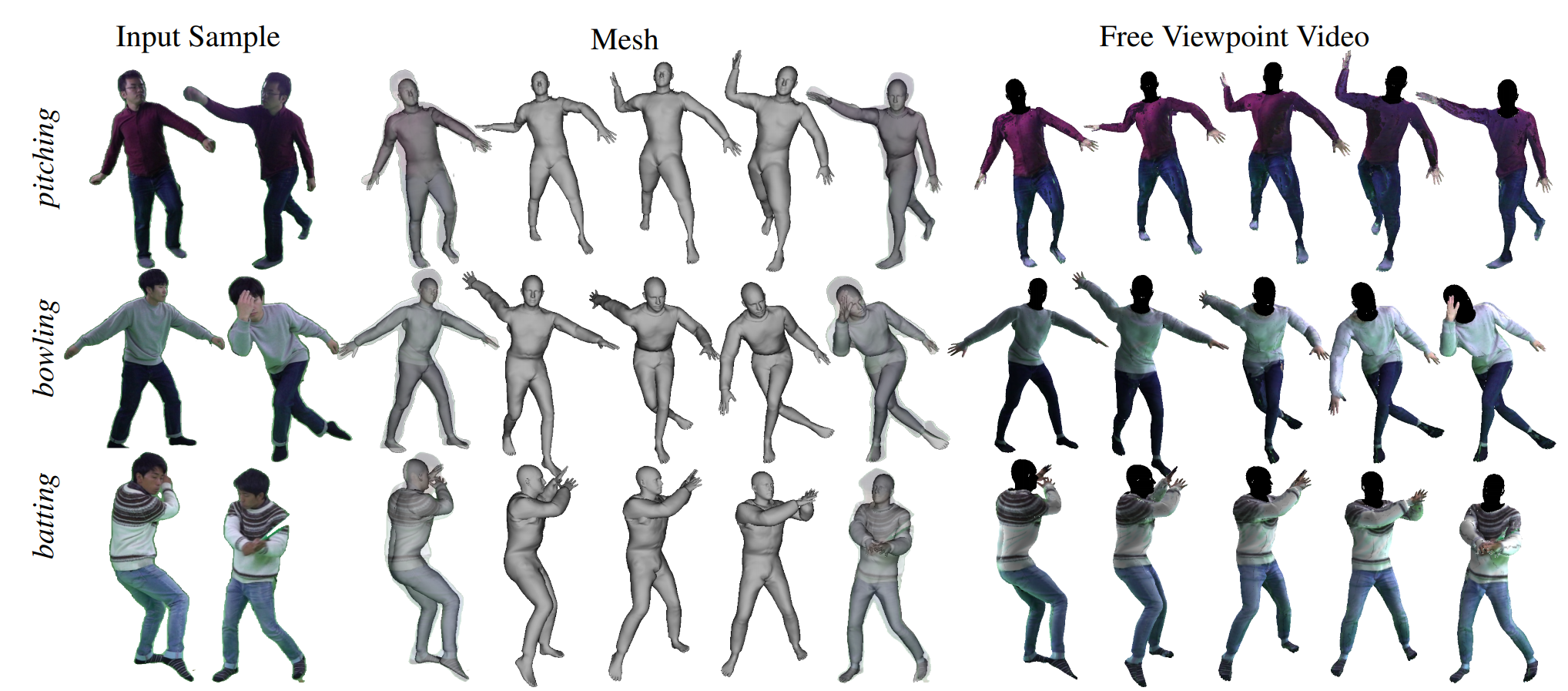Keisuke Shibata, Sangeun Lee, Shohei Nobuhara, and Ko Nishino
Kyoto University and JST PRESTO
We introduce a novel method for reconstructing the 3D human body from a video of a person in action. Our method recovers a single clothed body model that can explain all frames in the input. Our method builds on two key ideas: exploit the repeatability of human action and use the human body for camera calibration and anchoring. The input is a set of image sequences captured with a single camera at different viewpoints but of different instances of a repeatable action (e.g., batting). Detected 2D joints are used to calibrate the videos in space and time. The sparse viewpoints of the input videos are significantly increased by bone-anchored transformations into rest-pose. These virtually expanded calibrated camera views let us reconstruct surface points and free-form deform a mesh model to extract the frame-consistent personalized clothed body surface. In other words, we show how a casually taken video sequence can be converted into a calibrated dense multiview image set from which the 3D clothed body surface can be geometrically measured. We introduce two new datasets to validate the effectiveness of our method quantitatively and qualitatively and demonstrate free-viewpoint video playback.
Consistent 3D Human Shape from Repeatable Action
K. Shibata, S. Lee, S. Nobuhara, and K. Nishino,
in Proc. of IEEE International Conference on Computer Vision and Pattern Recognition Workshops CVPRW’21 (Int’l Workshop on Dynamic Scene Reconstruction), Jun., 2021. Best Paper Award
[ paper ][ project ][ talk ]
Talk
Overview
In this paper, we tackle the challenging problem of recovering a consistent 3D clothed human body model from a casually taken video of a person in action. We ask, instead of learning structural variations that seems infeasible for clothed shapes, can we actually “measure” the clothed body shape? Just from a short video of a person in temporally changing poses, can we recover one detailed clothed surface of the person such that it can be posed into every frame? We realize this by exploiting the repeatability of actions. Many actions are repeatable. For instance, sports actions such as golf swings and baseball pitching can be repeated with more or less the same body movements.
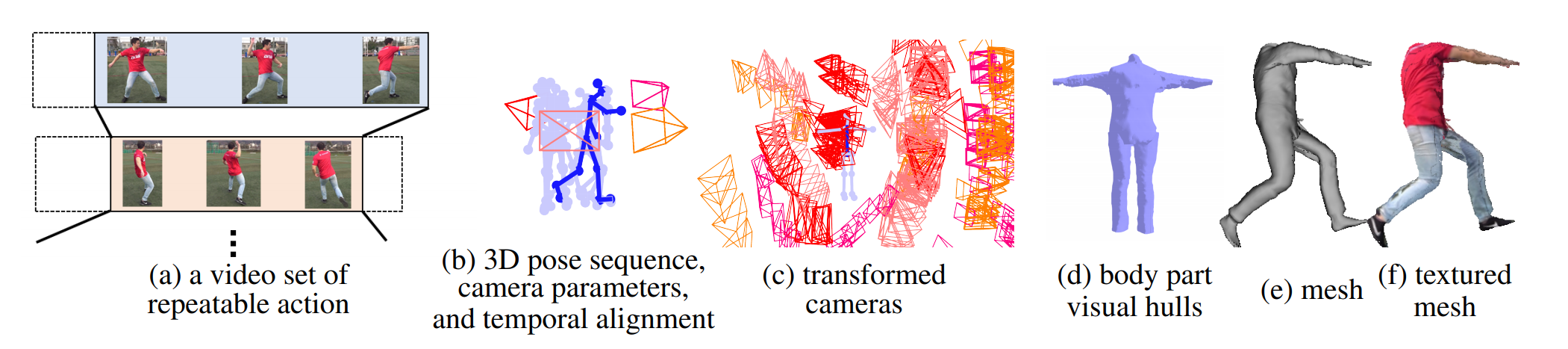
From a set of videos each capturing a different instance of a repeated action from a distinct viewpoint (a), we simultaneously recover human pose sequences, camera parameters, and temporal alignment (b). The 3D bones serve as anchors to the (bone-relative) viewpoint of each frame in each of the videos of different camera locations (each cone in distinct color, respectively) (c). These bone-anchored relative cameras are transformed into a common coordinate frame, which is used to construct a visual hull for each body part (d). A generic body surface model is free-form deformed to fit these visual hulls, resulting in a consistent clothed 3D body shape mesh model of the target person that can be rendered from a novel viewpoint with and without textures (e,f).
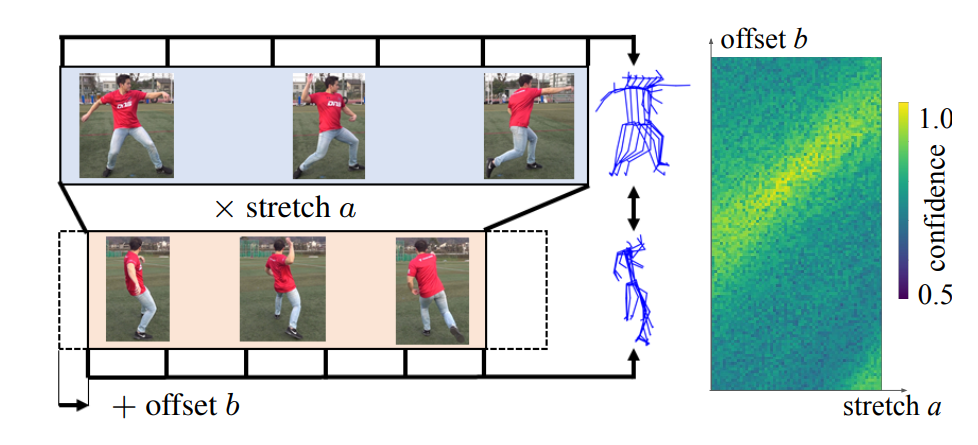
Given the repeatable action videos, our first step is to estimate the camera viewpoints while temporally aligning the sequences. We achieve this spatio-temporal calibration by leveraging the human body, in particular, its joints as calibration targets. The human body is unique in that its joints and bones form a rigid structure that can be articulated. That is, the relative distances between the joints do not vary as they move in coordination. We exploit this fact to spatially calibrate the multiple views and also estimate the temporal stretch and offsets of the videos.
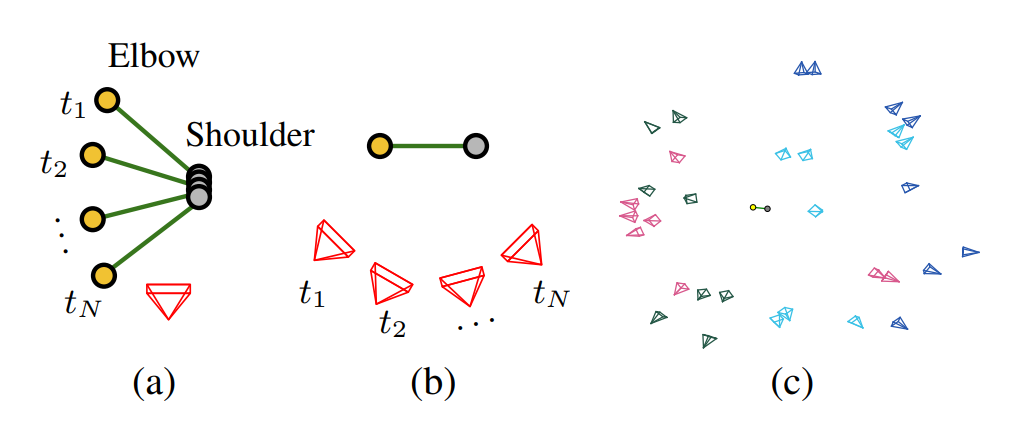
Our key insight is to reinterpret an articulated 3D human body in front of a fixed camera view (a) as virtual cameras anchored to static bones of a 3D human body in rest shape rotating around the body (b). We anchor cameras to the 3D bones and independently transform the 3D bone into the rest pose along with the cameras that capture the bone. Virtually duplicated and transformed cameras are now capturing a single static 3D body in rest pose, just like in a multiview studio (c).
Results
Our reconstructions accurately overlap the input images and are consistent with other views. Even though every action is a challenging pose sequence, the reconstruction result explains the input frames well.