Kohei Yamashita, Yuto Enyo, Shohei Nobuhara, and Ko Nishino
Kyoto University
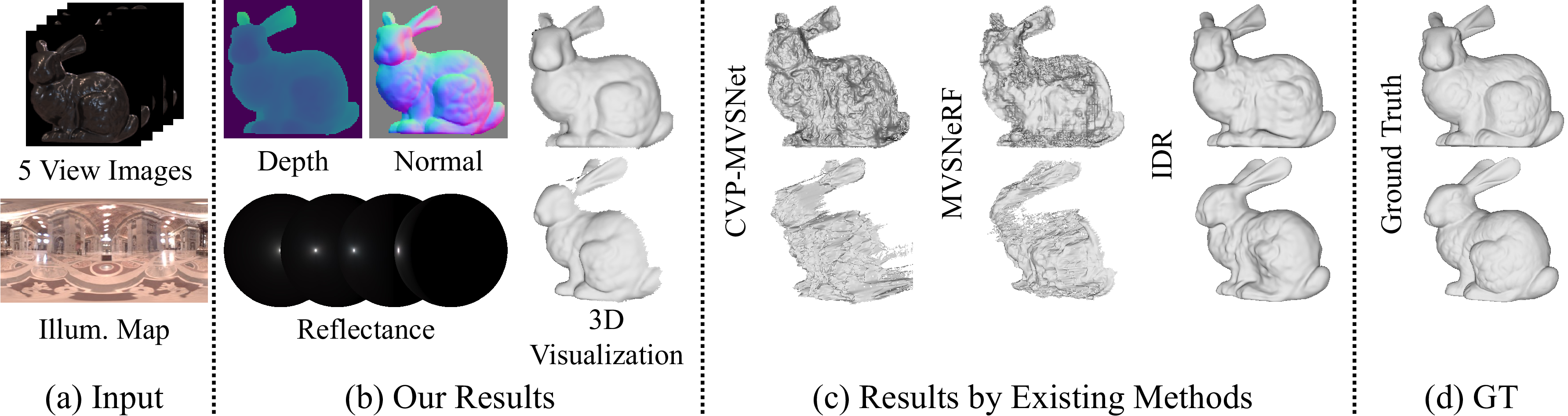
We introduce a novel multi-view stereo (MVS) method that can simultaneously recover not just per-pixel depth but also surface normals, together with the reflectance of textureless, complex non-Lambertian surfaces captured under known but natural illumination. Our key idea is to formulate MVS as an end-to-end learnable network, which we refer to as nLMVS-Net, that seamlessly integrates radiometric cues to leverage surface normals as view-independent surface features for learned cost volume construction and filtering. It first estimates surface normals as pixel-wise probability densities for each view with a novel shape-from-shading network. These per-pixel surface normal densities and the input multi-view images are then input to a novel cost volume filtering network that learns to recover per-pixel depth and surface normal. The reflectance is also explicitly estimated by alternating with geometry reconstruction. Extensive quantitative evaluations on newly established synthetic and real-world datasets show that nLMVS-Net can robustly and accurately recover the shape and reflectance of complex objects in natural settings.
nLMVS-Net: Deep Non-Lambertian Multi-View Stereo
K. Yamashita, Y. Enyo, S. Nobuhara, and K. Nishino,
in IEEE/CVF Winter Conference on Applications of Computer Vision WACV’23, 2023.
[ paper ][ supp. PDF ][ supp. video ][ project ][ code/data ]
Talk
nLMVS-Net
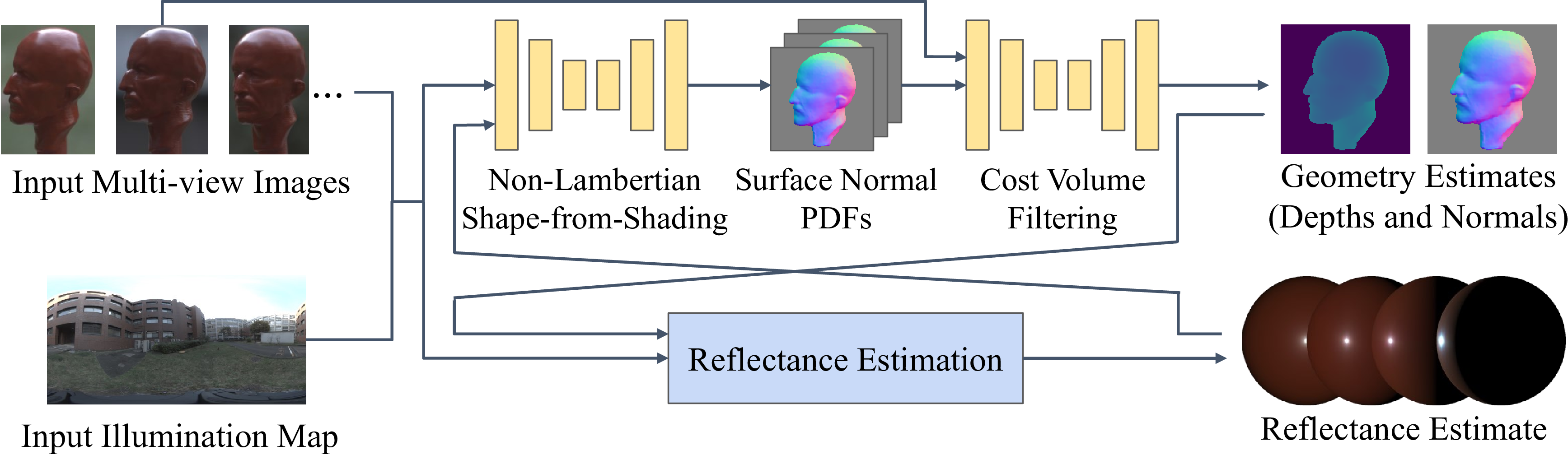
We integrate stereopsis with radiometric analysis so that radiometrically recovered geometric properties, namely surface normals, can serve as view-independent cues for multi-view stereopsis. We achieve this integration with two deep neural sub-networks. Given sparse (e.g., 5) multi-view images, an illumination map of the surrounding environment, and an initial reflectance estimate as inputs, the shape-from-shading sub-network recovers surface normals as per-pixel probability densities (PDFs) for each view. The novel cost volume filtering sub-network then learns to reconstruct per-pixel depth and surface normals from those and the input images. By alternating with neural reflectance estimation, we jointly recover the complex surface reflectance of the object.
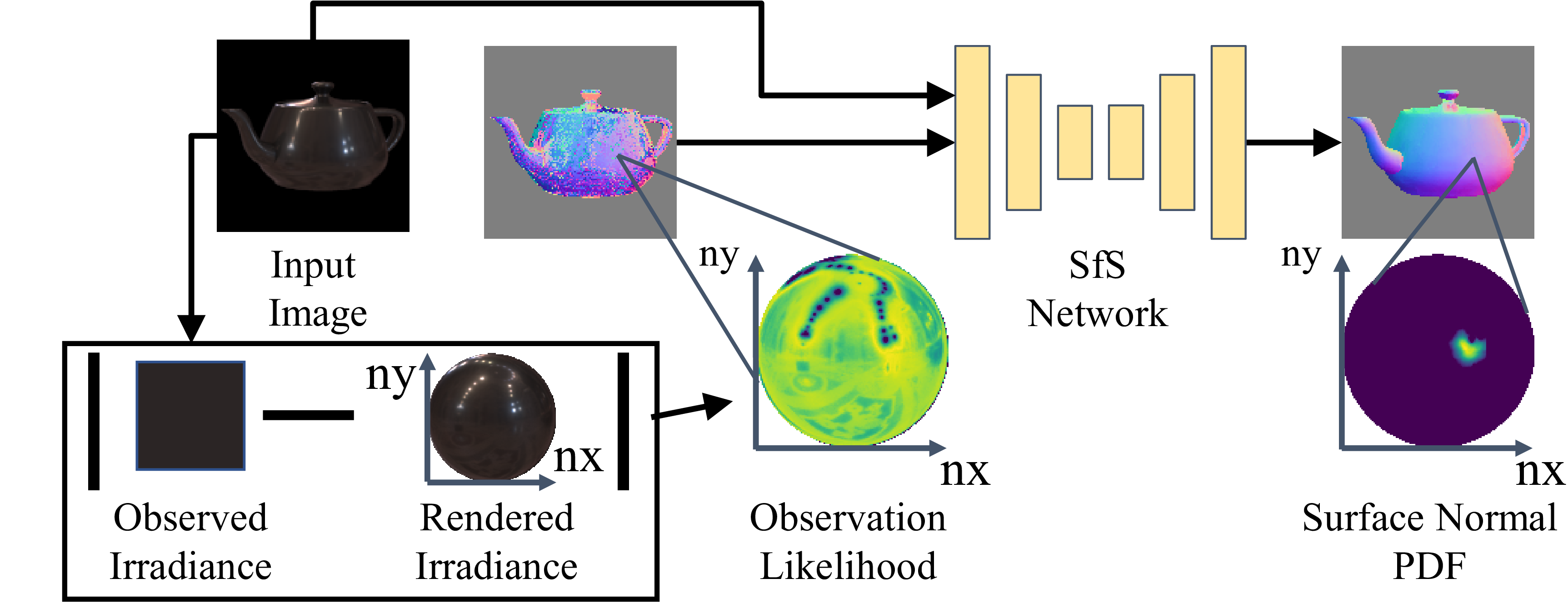
The shape-from-shading (SfS) sub-network fully leverages radiometric likelihood of surface normals. We compute the likelihood according to errors between observed irradiance and those rendered from the illumination map and the current reflectance estimate. The SfS network refines and converts the observation likelihoods into pixel-wise probability densities of surface normals by aggregating local and global contextual information across the surface.
nLMVS-Dataset
We also introduce two newly collected datasets, which we refer to as nLMVS-Synth and nLMVS-Real. The synthetic dataset (nLMVS-Synth) consists of 26850 rendered images of 2685 objects with 94 and 2685 different real-world reflectance and natural illumination, respectively. We use nLMVS-Synth to train nLMVS-Net and thoroughly evaluate its accuracy on unseen synthetic images. The new multi-view image dataset of real objects, namely nLMVS-Real, consists of 2569 multi-view images of 5 objects each with one of 4 different reflectances taken under 6 different natural illuminations. Each of the 5 different objects is replicated with a 3D printer so that accurate ground truth geometry is available for quantitative analysis. This dataset is unprecedented in size for an accurately radiometrically and geometrically calibrated multi-view image set for a variety of surfaces and would undoubtedly serve as a useful platform for a wide range of shape reconstruction and inverse rendering research.
Results
These show recovered depths, surface normals, and reflectance from our nLMVS-Synth and nLMVS-Real datasets. The results demonstrate that our method successfully recovers accurate geometry and complex reflectance for a wide variety of objects.
We also show that the recovered depths, surface normals, and reflectance can be used for whole 3D object shape recovery and free viewpoint relighting. Please see the supplemental video for more results.