Yupeng Liang, Ryosuke Wakaki, Shohei Nobuhara, and Ko Nishino
Kyoto University
We realize multimodal material segmentation, the recognition of per-pixel material categories from a set of images from the same vantage point but with different imaging modalities. In particular, we consider the combination of regular RGB, polarization, and near-infrared images at each instance. We introduce a new dataset of multimodal material images which we refer to as the MCubeS dataset (from MultiModal Material Segmentation). We also derive a novel deep architecture, which we refer to as MCubeSNet, for learning to accurately achieve multimodal material segmentation. We introduce region-guided filter selection (RGFS) to let MCubeSNet learn to focus on the most informative combinations of imaging modalities for each material class. We use object categories obtained with vanilla semantic segmentation as a prior to ‘‘guide’’ the filter selection. The network learns to select different convolution filters for each semantic class from a learned image-wise set of filters. This region-guided filter selection layer enables ‘‘dynamic’’ selection of filters, and thus combinations of imaging modalities, tailored to different potential materials underlying different semantic regions (i.e., object categories) without significant computational overhead.
Multimodal Material Segmentation
Y. Liang, R. Wakaki, S. Nobuhara, and K. Nishino,
in Proc. of Conference on Computer Vision and Pattern Recognition CVPR’22, Jun., 2022.
[ paper ][ supp. pdf ][ supp. video ][ project ][ code/data ]
Supplementary Video
MCubeS dataset
MCubeS captures the visual appearance of various materials found in daily outdoor scenes from a viewpoint on a road, pavement, or sidewalk. At each viewpoint, we capture images with three fundamentally different imaging modalities: RGB, polarization, and near-infrared (NIR). MCubeS dataset captures these rich radiometric characteristics of different materials with a camera system consisting of a stereo pair of RGB-polarization (RGB-P) camera and a near-infrared (NIR) camera. All cameras are mounted on a cart to collect multimodal sequences of real-world scenes from a vantage point similar to a car. The image capture system is also equipped with a LiDAR to assist label propagation. We define 20 distinct materials by thoroughly examining the data we captured in the MCubeS dataset.
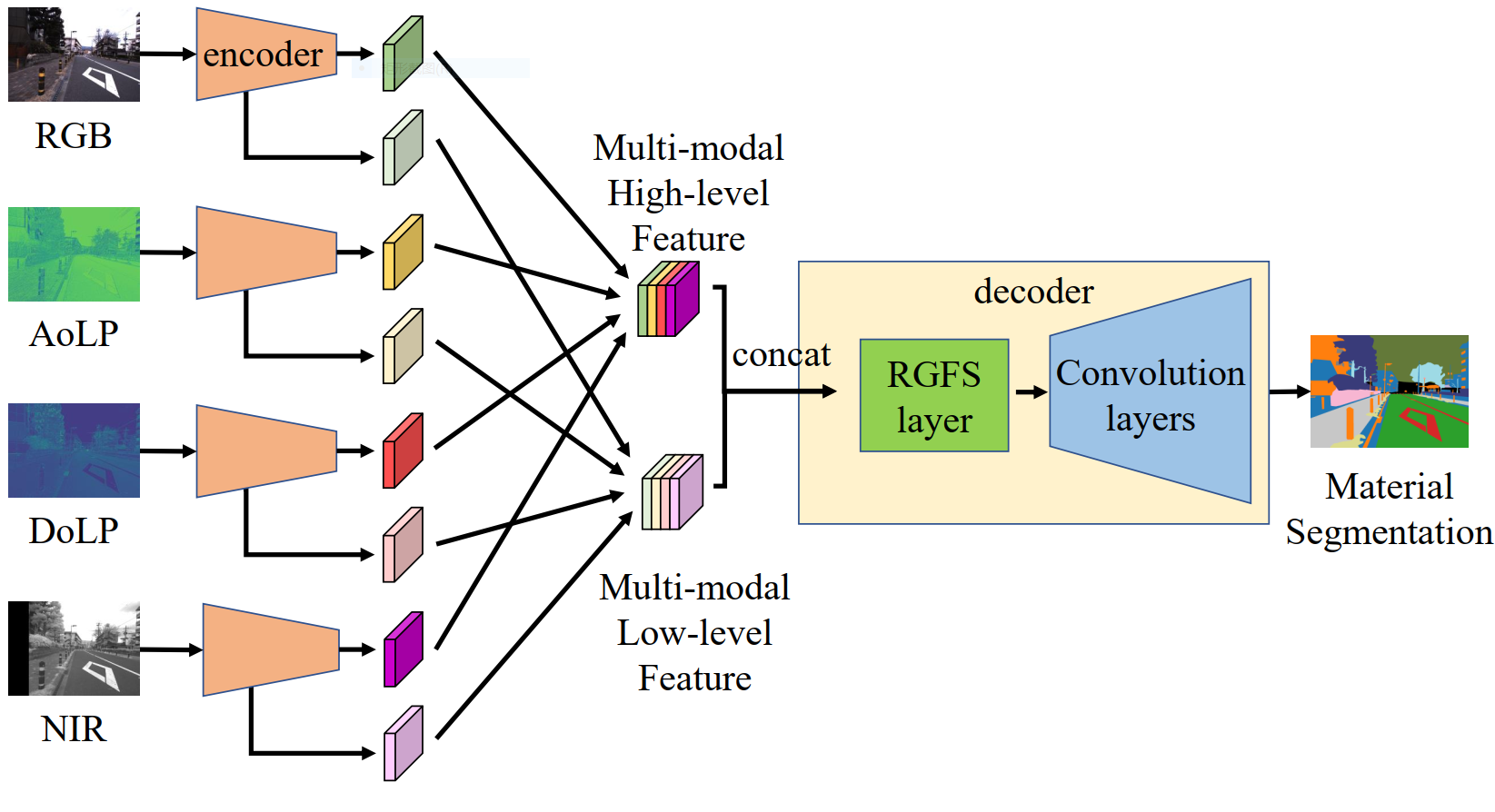
MCubeSNet
The MCubeSNet is based on the Deeplab v3+. Since different imaging modalities contains information from different aspect, we use separate encoders for each image modality. The high-level features are upsampled four times and concatenated with the low-level features which is then input to the decoder.
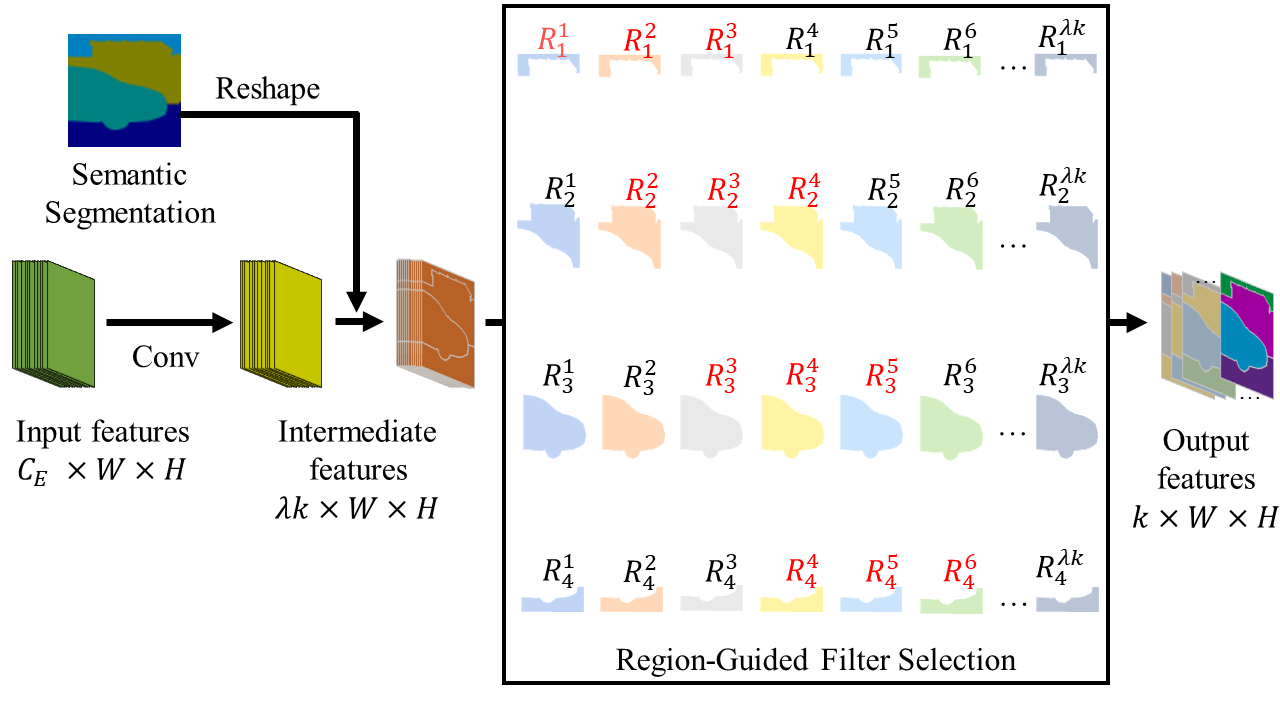
Material occurrences are strongly correlated with object instances. We leverage this rich interdependence between objects and materials by using object categories as priors on material segmentation. Our key idea is to learn an overcomplete set of (regular) convolutional filters across the entire image, but learn to assign different sets of those filters to each semantic region. The filters are selected by picking the top k responsive filters for each semantic region, i.e., picking the filters that have the highest average activation. This approach enables the learning of material-specific filter sets that integrate different imaging modalities (channels of encoder output features) with different weightings guided by semantic regions, which we refer to as RGFSConv.
Results
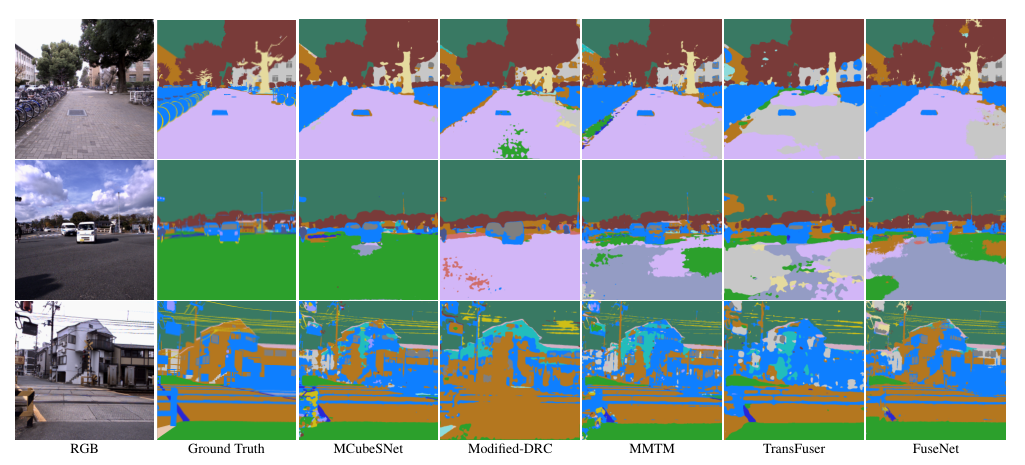
Performance comparison of MCubeSNet, deeplab v3+ and other methods. The results demonstrate that our MCubeSNet achieves more accurate segmentation results. MCubeSNet, for instance, can discriminate the rail track from its surrounding concrete and overall performs better in recognizing the road.
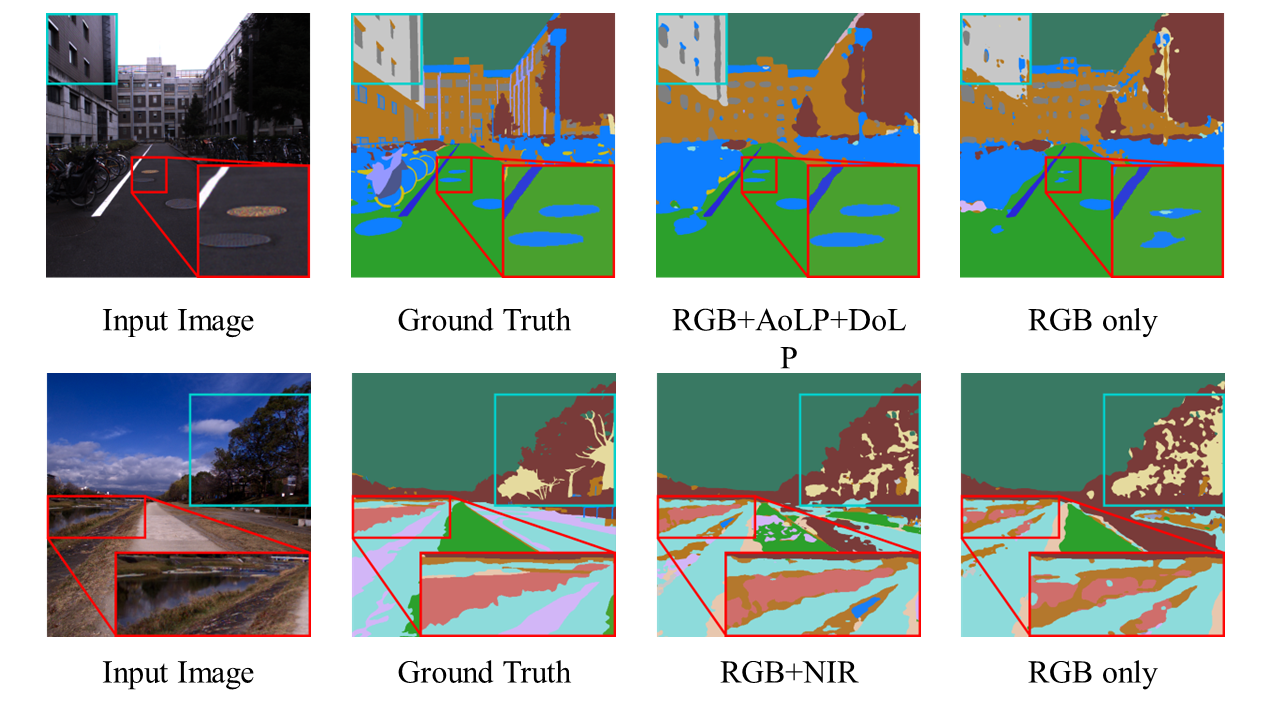
Contribution of polarization and NIR for material segmentation. The results demonstrate that polarization behavior adds significant information to achieve higher accuracy, especially for discerning metal and dielectrics. And NIR helps recognize water (river) and wet surfaces (wood vs. leaves).