Camera Height Doesn’t Change Unsupervised Training for Metric Monocular Road-Scene Depth Estimation
Genki Kinoshita and Ko Nishino
Kyoto University
We introduce a novel training method for making any monocular depth network learn absolute scale and estimate metric road-scene depth just from regular training data, i.e., driving videos. We refer to this training framework as FUMET. The key idea is to leverage cars found on the road as sources of scale supervision and to incorporate them in network training robustly. FUMET detects and estimates the sizes of cars in a frame and aggregates scale information extracted from them into an estimate of the camera height whose consistency across the entire video sequence is enforced as scale supervision. This realizes robust unsupervised training of any, otherwise scale-oblivious, monocular depth network so that they become not only scale-aware but also metric-accurate without the need for auxiliary sensors and extra supervision. Extensive experiments on the KITTI and the Cityscapes datasets show the effectiveness of FUMET, which achieves state-of-the-art accuracy. We also show that FUMET enables training on mixed datasets of different camera heights, which leads to larger-scale training and better generalization. Metric depth reconstruction is essential in any road-scene visual modeling, and FUMET democratizes its deployment by establishing the means to convert any model into a metric depth estimator.
Camera Height Doesn’t Change: Unsupervised Training for Metric Monocular Road-Scene Depth Estimation
G. Kinoshita, and K. Nishino,
in European Conference on Computer Vision (ECCV), 2024.
[ paper ][ supp. PDF ][ project ][ code/data ]
Method
As the overview animation shows, we introduce a learned size prior (LSP) to estimate the size of each car found in a frame. This prior gives us the vehicle dimensions from its appearance. It is trained with various augmentations on a large-scale dataset without the need for any manual annotation. By comparing these dimension estimates with those computed from the depth estimates, we obtain a per-frame scale factor. The multiplication of this scale estimate with the camera height estimate derived from the estimated depth becomes the camera height estimate of the frame. These estimated camera heights across all frames in a sequence are then consolidated by using their median value which is then used as scale supervision with its weighted moving average at the end of each training epoch.
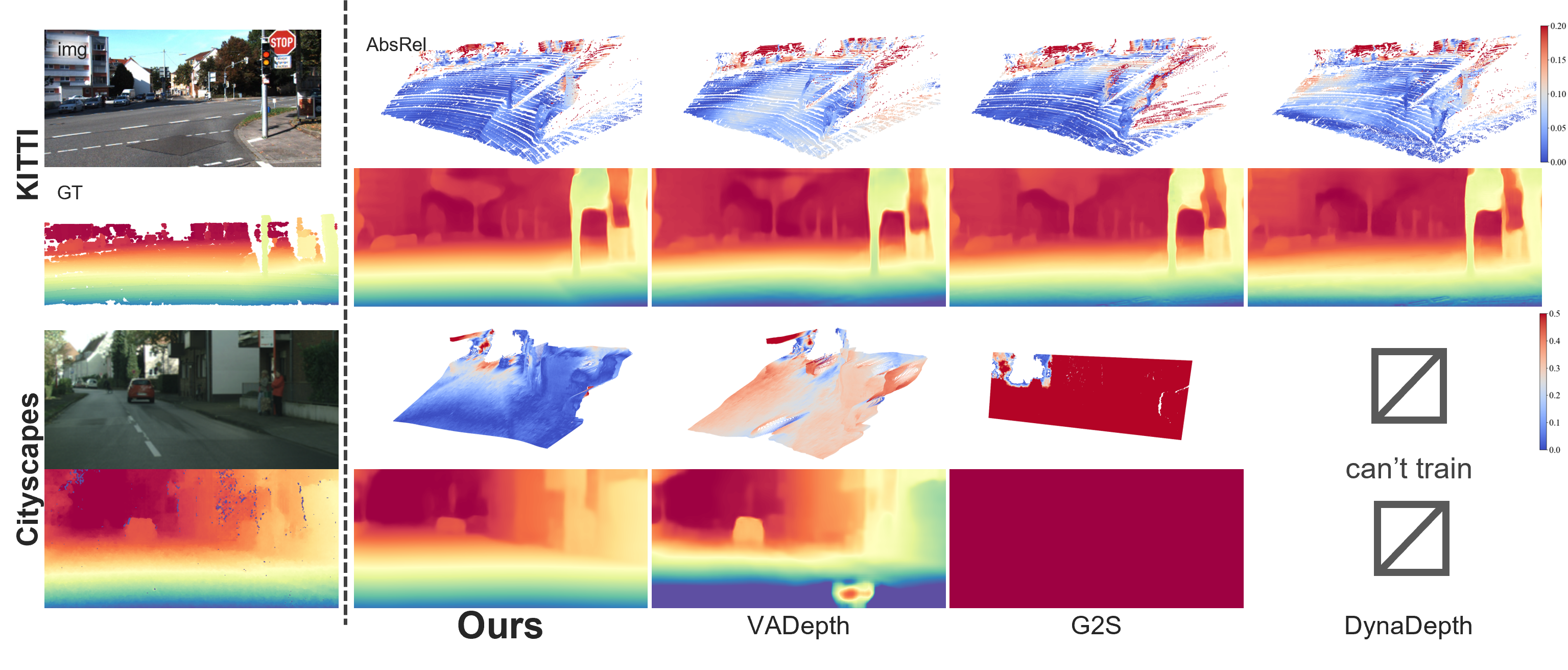
Results
FUMET can make a model learn metric scale and it achieves better accuracy than weakly supervised models, even when they are trained with ground-truth camera height. Especially on the Cityscapes dataset, FUMET outperforms others by a wide margin. These methods assume that highly accurate sensor data is available and fail to learn metric scale on datasets consisting of unreliable sensor data such as Cityscapes. On the other hand, FUMET does not require any sensor measurement other than RGB video, so it can robustly leverage any driving videos for training.
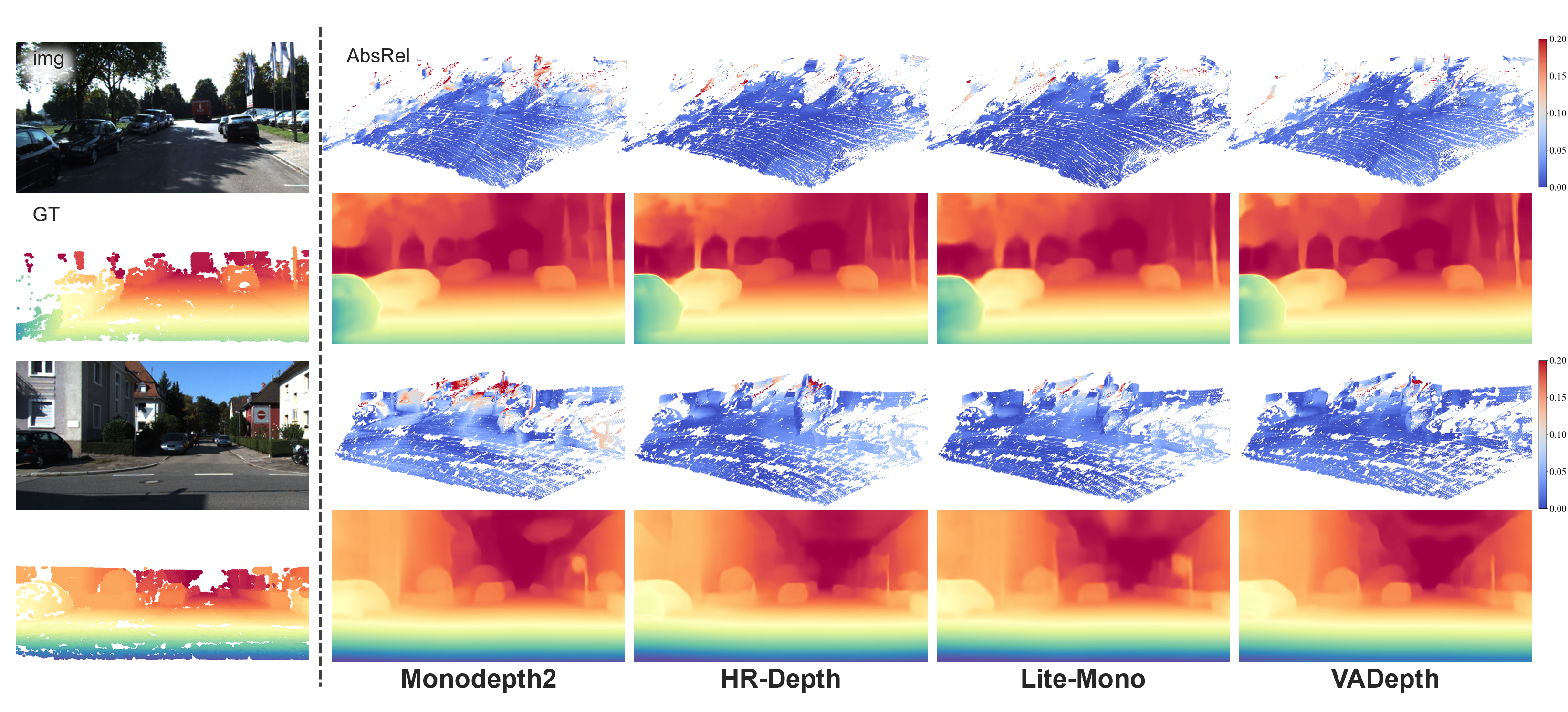
FUMET enables various architectures to learn metric scale properly.
Training on mixed datasets of various camera heights
FUMET enables training on mixed datasets of different camera heights by creating pseudo labels corresponding to each camera height and optimizing them individually. This leads to larger-scale training and better generalization. The figure above illustrates the zero-shot performance on NuScenes of the model trained on the mixed dataset including Argoverse2, Lyft, A2D2, and DDAD.