DeePoint: Visual Pointing Recognition and Direction Estimation
Shu Nakamura1, Yasutomo Kawanishi2,
Shohei Nobuhara1, and Ko Nishino1,2 1Kyoto University 2RIKEN
We introduce DeePoint, a neural pointing recognition and 3D direction estimator. DeePoint trained on our newly constructed DP Dataset recognizes when a person is pointing and estimates its 3D direction from video frames captured from a fixed-view camera. Each arrow depicts the pointing direction. Its color is green when the person is pointing, red when not. DeePoint successfully recognizes when a pointing starts and ends and can estimate its 3D direction from the complex spatio-temporal coordination of the person’s body.
DeePoint: Visual Pointing Recognition and Direction Estimation
S. Nakamura, Y. Kawanishi, S. Nobuhara, and K. Nishino,
in IEEE International Conference on Computer Vision (ICCV), 2023.
[ arXiv ][ paper ][ supp. PDF ][ supp. video ][ project ][ code/data ]
Video
DP Dataset
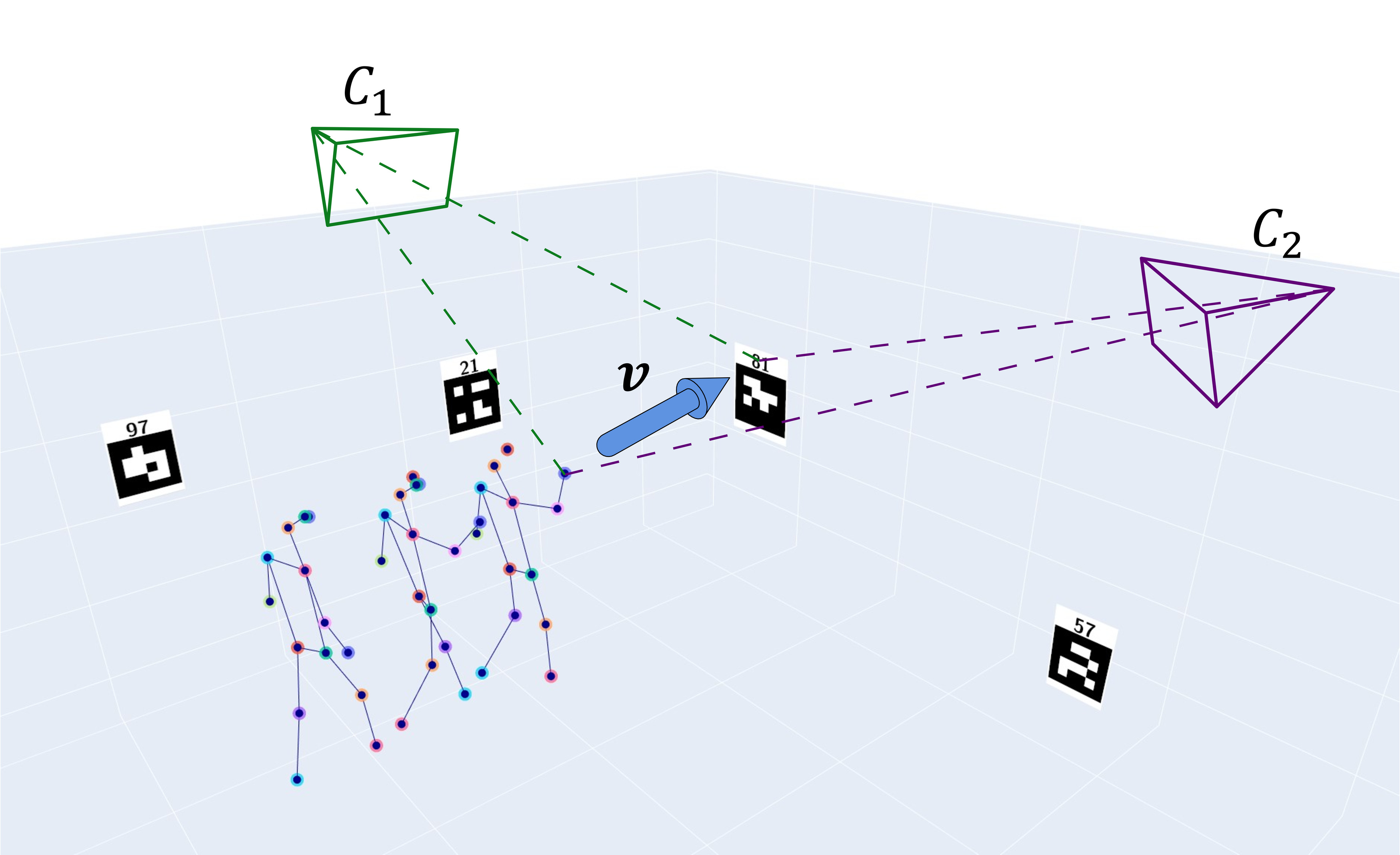
We introduce the DP Dataset, which consists of fixed-view videos of 33 male and female participants, uniformly ranging in generations from their twenties to sixties, pointing at random markers. We capture each participants for about 5 minutes, allowing them to freely roam around the room. We mount cameras at fixed viewpoints in two rooms with ~40 target markers to capture the pointing gestures from a variety of directions at once. In total, the dataset contains about 2,800,000 frames, with frames with pointing spanning 770,000 frames capturing 6,355 unique pointing instances.
We automatically annotate the 3D directions of each pointing instance with multi-view geometry. By identifying the marker to which the person is pointing from recorded audio and triangulating the marker and hand location, we compute the unit 3D vector annotation for the 3D pointing direction.
DeePoint
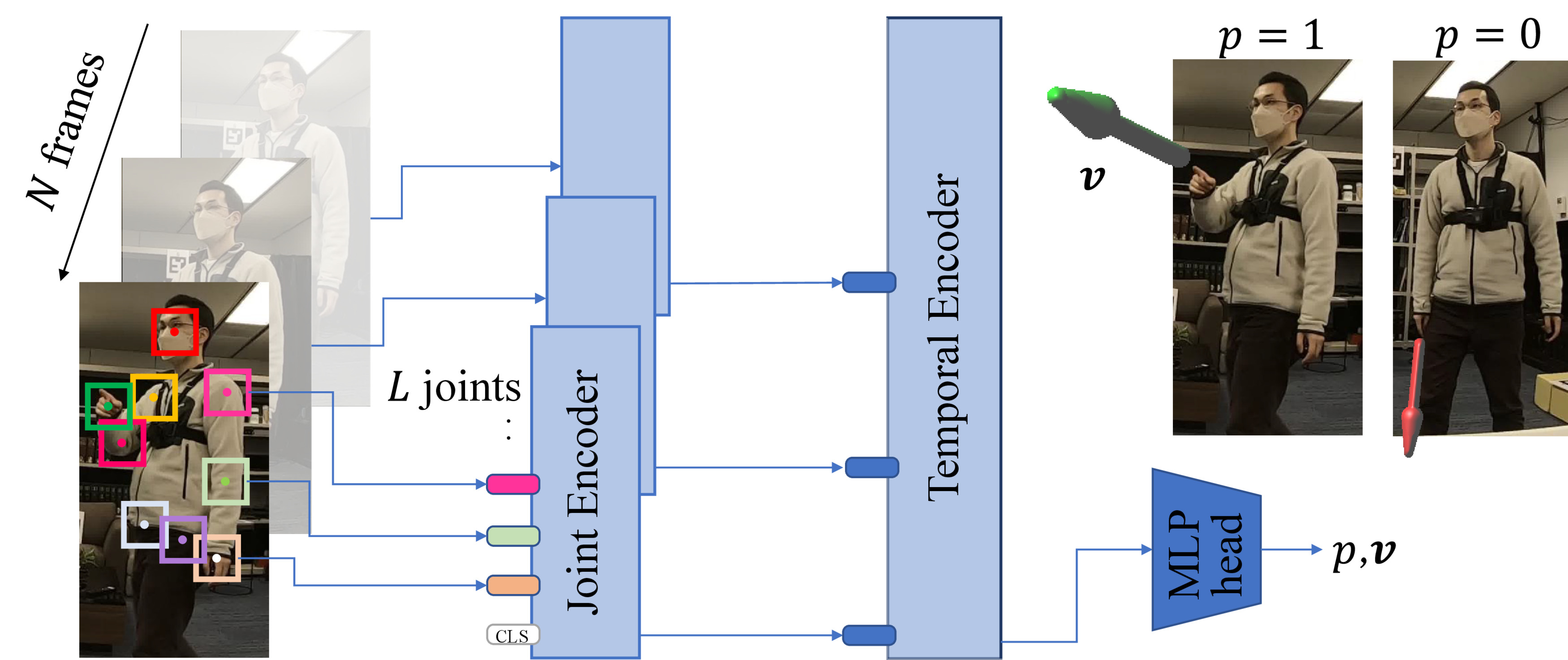
We introduce DeePoint, a novel method for accurate pointing recognition and 3D direction estimation that leverages attention for spatio-temporal information aggregation. Given a sequence of input frames, DeePoint first detects the joints using an off-the-shelf 2D human pose estimator, and extracts visual features around them. The visual features are first processed by Joint Encoder in a frame-wise manner, and then fed to Temporal Encoder to integrate features from multiple frames. The output of Temporal Encoder is transformed by an MLP head to the probability indicating whether the target is in a pointing action, and its 3D direction in the camera coordinate system. DeePoint is trained on the DP Dataset.
Results
We applied DeePoint to the test set of the DP Dataset. In each image, the blue arrow denotes the ground truth direction and the other arrow denotes the estimated 3D direction by DeePoint. Note how DeePoint correctly recognizes the timing of pointing. For instance, it learns to recognize when the person looks away as the finish of pointing and finds the onset of pointing from change in speed of the movements of the body coordination.
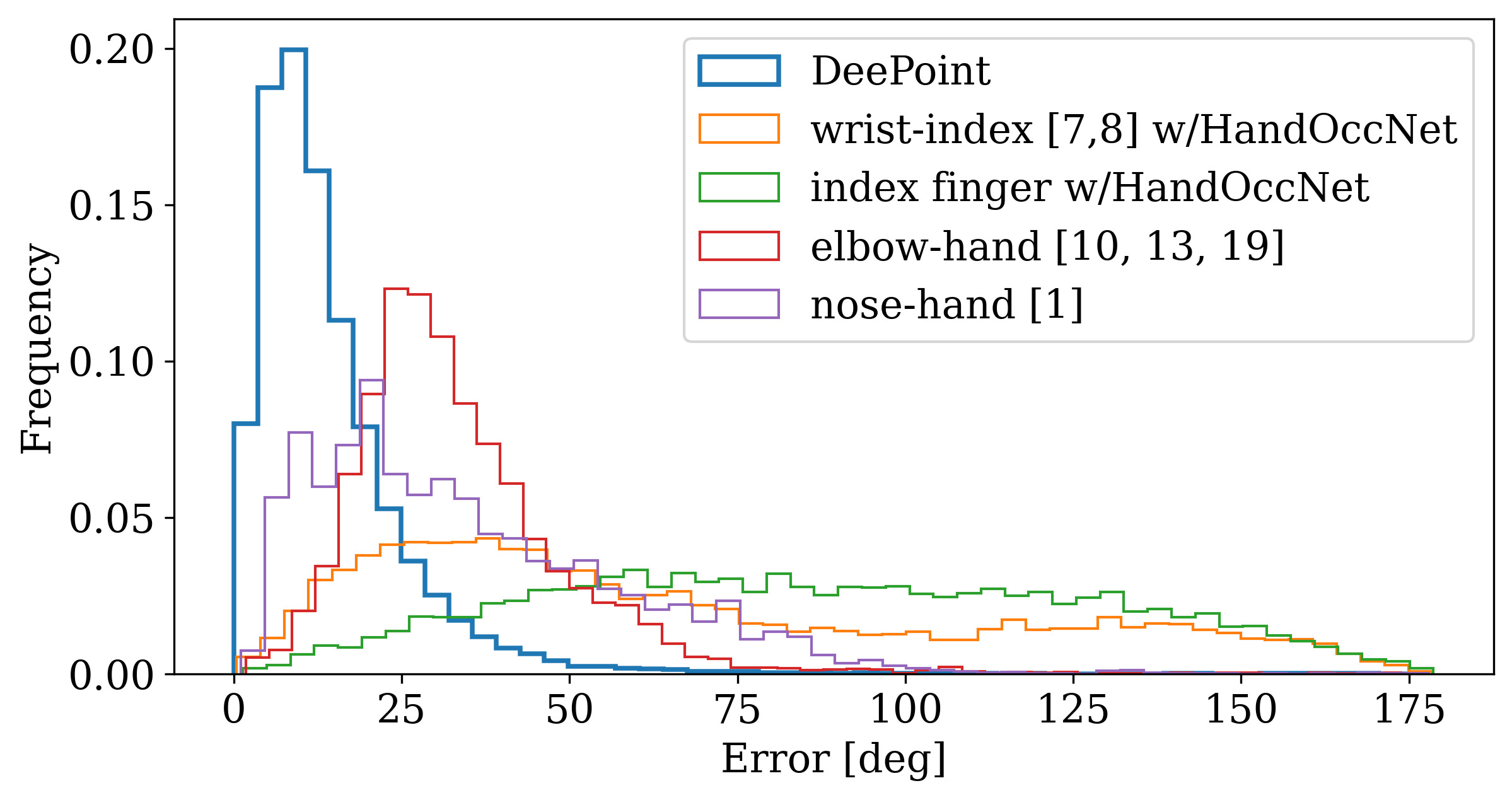
We evaluated past methods on the DP Dataset and compared with DeePoint. We use HandOccNet (Park et al., 2022) to recover a 3D hand mesh and use the recovered hand to estimate the pointing direction. We also replicated geometry-based approaches using the triangulated 3D keypoints of the DP dataset. DeePoint clearly outperforms all.
We applied DeePoint to the PKU-MMD dataset (Chunhui et al., 2017). Note that our model is not retrained on the PKU-MMD and applied out-of-the-box. DeePoint generalizes well to a completely different dataset. Please see the supplementary video for more examples.