Sang-Eun Lee1, Keisuke Shibata1, Soma Nonaka1, Shohei Nobuhara1,2, and Ko Nishino1 1 Kyoto University 2 JST PRESTO
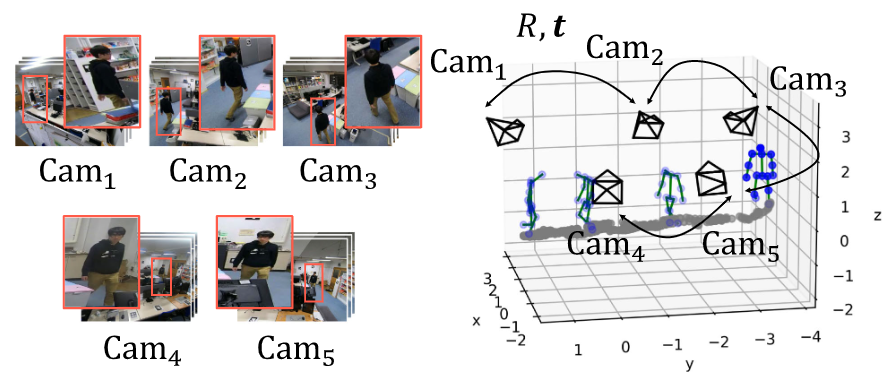
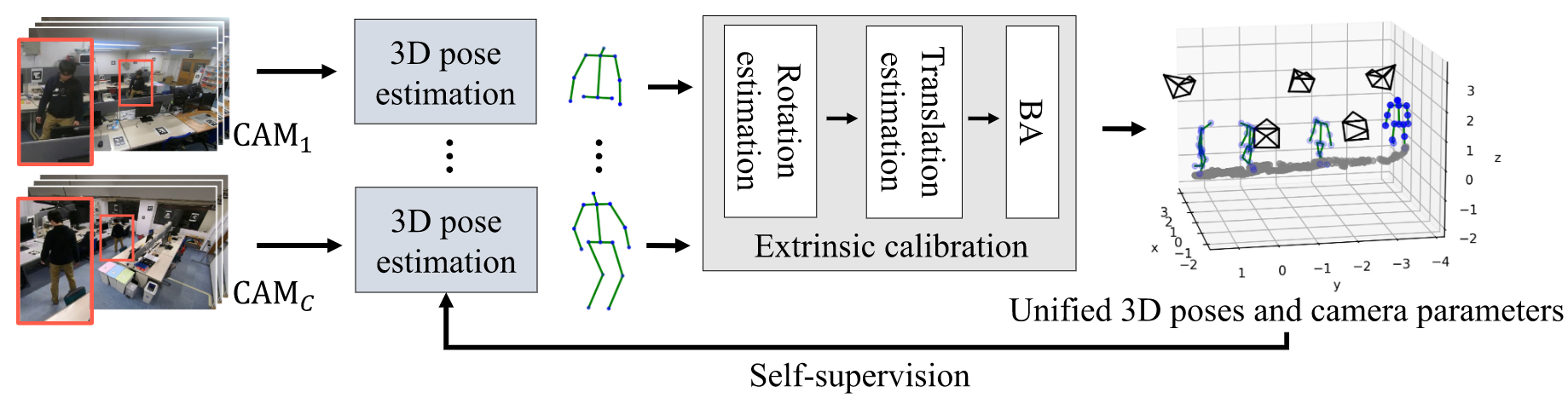
We propose a novel camera calibration method for a room-scale multi-view imaging system. Our key idea is to leverage our articulated body movements as a calibration target. We show that a freely moving person provides trajectories of a set of oriented points (e.g., neck joint with spine direction) from which we can estimate the locations and poses of all cameras observing them. The method only requires the cameras to be synced and that 2D human poses are estimated in each view sequence. By elevating these 2D poses to 3D which directly provides a set of oriented 3D joints, we compute the extrinsic parameters of all cameras with a linear algorithm. We also show that this enables self-supervision of the 3D joint estimator for refinement, and the iteration of the two leads to accurate camera extrinsics and 3D pose estimates up to scale. Extensive experiments using synthetic and real data demonstrate the effectiveness and flexibility of the method. The method will serve as a useful tool to expand the utility of multi-view vision systems as it eliminates the need for cumbersome on-site calibration procedures.
Extrinsic Camera Calibration From a Moving Person
S. -E. Lee, K. Shibata, S. Nonaka, S. Nobuhara and K. Nishino,
in IEEE Robotics and Automation Letters (RA-L) (also IEEE/RSJ International Conference on Intelligent Robotics and Systems IROS’22), vol. 7, no. 4, pp. 10344-10351, 2022.
[ paper ][ talk ][ project ][ code/data ]
Presentation Video at IROS 2022
Extrinsic Camera Calibration From a Moving Person
Our method calibrates multiple camerasby just observing us, freely moving people. The key idea is to exploit the fact that our body is articulated. It serves as a calibration target with a length-preserved kinematic structure (i.e., bone length) and easily matchable point correspondences (i.e., joints).
We utilize off-the-shelf monocular 2D and 3D human pose estimators, and use their outputs as 3D oriented points for calibration. Once the calibration is done, we can triangulate the 3D human poses which serve as a supervision to fine-tune the monocular human pose estimator. By iterating this calibration and self-supervised fine-tuning, our method can estimate the 3D human poses together with the camera poses as a fully-automatic markerless 3D motion capture.
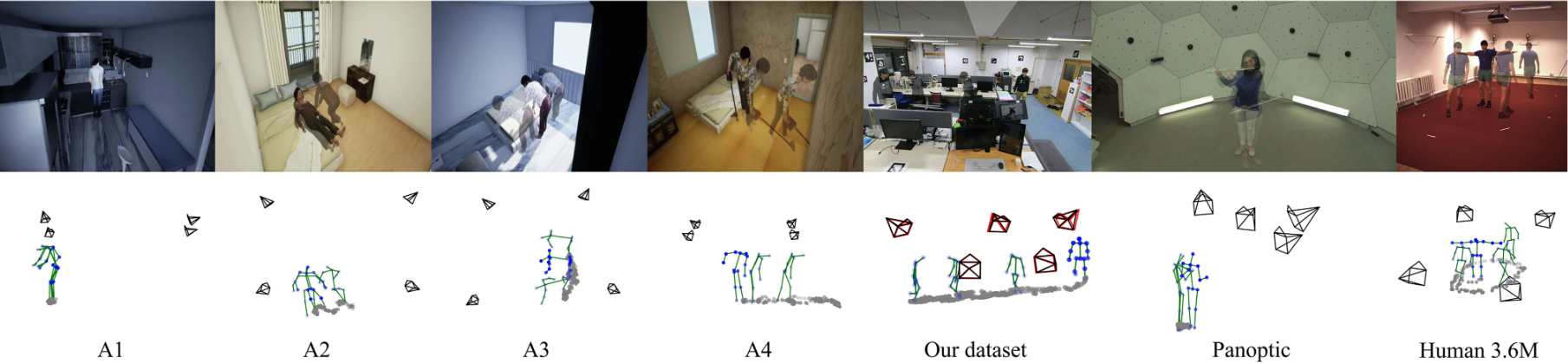
Results
Our method can calibrate the cameras reliably even from a small daily motion sequence, in contrast to conventional calibration methods that rely on a calibration target being moved across the scene, which is often challenging to realize. These results demonstrate the effectiveness of our method, especially as a convenient calibration method for elderly support applications.