Taichi Fukuda, Kotaro Hasegawa, Shinya Ishizaki,
Shohei Nobuhara, and Ko Nishino
Kyoto University
We introduce 2D blind spot estimation as a critical visual task for road scene understanding. By automatically detecting road regions that are occluded from the vehicle’s vantage point, we can proactively alert a manual driver or a self-driving system to potential causes of accidents (e.g., draw attention to a road region from which a child may spring out). Detecting blind spots in full 3D would be challenging, as 3D reasoning on the fly even if the car is equipped with LiDAR would be prohibitively expensive and error prone. We instead propose to learn to estimate blind spots in 2D, just from a monocular camera. We achieve this in two steps. We first introduce an automatic method for generating ground-truth blind spot training data for arbitrary driving videos by leveraging monocular depth estimation, semantic segmentation, and SLAM. The key idea is to reason in 3D but from 2D images by defining blind spots as those road regions that are currently invisible but become visible in the near future. We construct a large-scale dataset with this automatic offline blind spot estimation, which we refer to as Road Blind Spot (RBS) dataset. Next, we introduce BlindSpotNet, a simple network that fully leverages this dataset for fully automatic estimation of frame-wise blind spot probability maps for arbitrary driving videos. Extensive experimental results demonstrate the validity of our RBS Dataset and the effectiveness of our BlindSpotNet.
BlindSpotNet: Seeing Where We Cannot See
T. Fukuda, K. Hasegawa, S. Ishizaki, S. Nobuhara and K. Nishino,
in European Conference on Computer Vision Workshops, Autonomous Vehicle Vision Workshop, 2022.
[ paper ][ talk ][ project ]
Supplementary Video
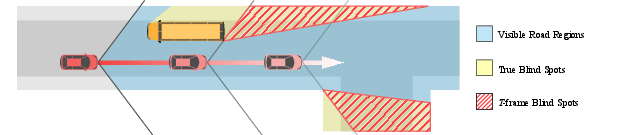
T-Frame Blind Spots
In the most general form, blind spots are volumes of the 3D space that are occluded from the viewpoint by an object in the scene. Computing these full blind volumes would be prohibitively expensive, especially for any application that requires real-time decision making. Even though our goal in this paper is not necessarily real-time computation at this point, a full 3D reasoning of occluded volumes would be undesirable as our target scenes are dynamic. We, instead, aim to estimate 2D blind spots on the road by defining them as road regions that are currently invisible but visible in the next T -frames, which we compute by aggregating road regions across future frames and subtracting the visible road region in the current frame. These T -frame blind spots form a subset of true blind spots, cover key regions of them and, most important, can directly be computed for arbitrary driving video.
Road Blind Spot Dataset
T-frame blind spots can be computed for each frame of arbitrary road scene videos. We use use MiDAS as the monocular depth estimator, OpenVSLAM for SLAM, and Panoptic-DeepLab for semantic segmentation. The scale of the depth estimated by MiDAS is linearly aligned with least squares fitting to the sparse 3D landmarks recovered by SLAM. We use KITTI~\cite{Geiger2013IJRR}, BDD100k~\cite{yu2020bdd100k}, and TITAN~\cite{malla2020titan} datasets to build our RBS Dataset. By excluding videos for which the linear correlation coefficient in the MiDAS-to-SLAM depth alignment is less than 0.7, they provide 51, 62, and 118 videos, respectively. We obtain blind spot masks for approximately 51, 34, and 12 minutes of videos in total, respectively. We refer to them as KITTI-RBS, BDD-RBS, and TITAN-RBS Datasets, respectively.
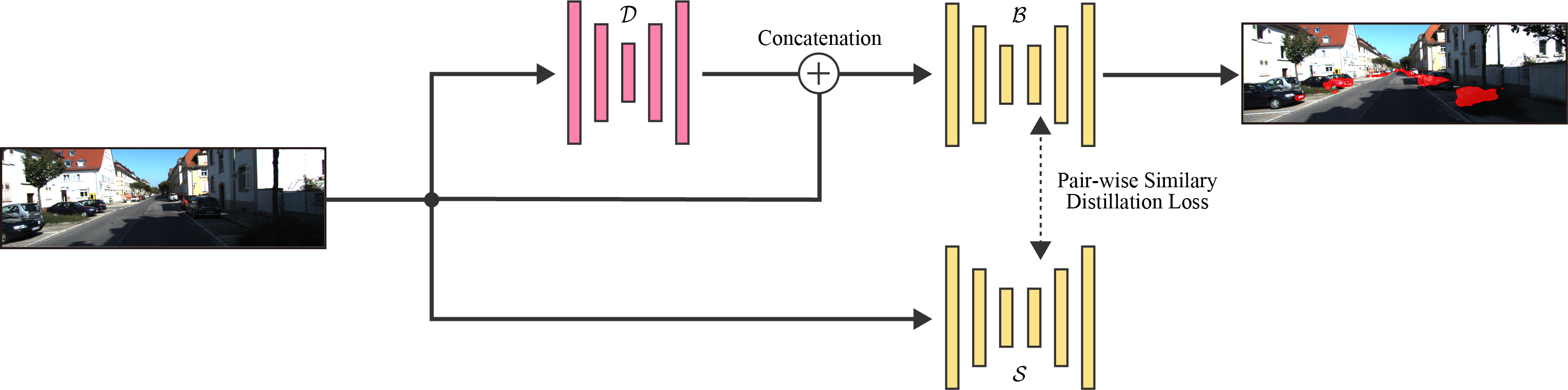
BlindSpotNet
Blind spots are mainly determined by the scene composition of objects and their ordering in 2D. As such, at a higher level, direct image-based estimation of blind spots shares similarity in its task to semantic segmentation. The task is, however, not necessarily easier, as it is 2D dense labeling but requires implicit 3D reasoning. Nevertheless, the output is a binary map (or its probability map), which suggests that a simpler network but with a similar representation to semantic segmentation would be suitable for blind spot detection. We leverage the fact that blind spot estimation bears similarity to semantic segmentation by adopting a light-weight network trained with knowledge distillation from a semantic segmentation teacher network.
Results
These show the results on the test sets from KITTI-RBS, BDD-RBS, and TITAN-RBS Datasets. The lines with w/ KITTI-RBS and w/ BDD-RBS indicate the results of the networks trained with KITTI-RBS and BDD-RBS, respectively. Each network, after pre-training, was fine-tuned using 20% of the training data of the target dataset to absorb scene biases. It is worth mentioning that this fine-tuning is closer to self-supervision as the T-frame blind spots can be automatically computed without any external supervision for arbitrary videos. As such, BlindSpotNet can be applied to any driving video without suffering from domain gaps, as long as a small amount of video can be acquired before running BlindSpotNet for inference. The 20% training data usage of the target scene simulates such a scenario. Note that none of the test data were used and this fine-tuning was not done for TITAN-RBS. BlindSpotNet outperforms Traversable, Detection-2D, and Detection-3D. These results show that blind spot estimation cannot be achieved by simply estimating footprint or behind-the-vehicle/pedestrian/cyclist regions.
Please see the presentation video for more results.