Video Region Annotation with Sparse Bounding Boxes
Yuzheng Xu, Yang Wu, Nur Sabrina binti Zuraimi,
Shohei Nobuhara and, Ko Nishino
Kyoto University
We introduce a novel dense video annotation method that only requires sparse bounding box supervision. We fit an iteratively deforming volumetric graph to the video sub-sequence bounded by two chosen keyframes, so that its uniformly initialized graph nodes gradually move to the key points on the sequence of region boundaries. The model consists of a set of deep neural networks, including normal convolutional networks for frame-wise feature map extraction and a volumetric graph convolutional network for iterative boundary point finding. By propagating and integrating node-associated information (sampled from feature maps) over graph edges, a content-agnostic prediction model is learned for estimating graph node location shifts. The effectiveness and superiority of the proposed model and its major components are demonstrated on two latest public datasets: a large synthetic dataset Synthia and a real dataset named KITTI-MOTS capturing natural driving scenes.
Video Region Annotation with Sparse Bounding Boxes
Y. Xu, Y. Wu, NS. Zuraimi, S. Nobuhara, and K. Nishino,
in Proc. of British Machine Vision Conference BMVC’20, Sep., 2020. (Oral) Best Student Paper Award
[ paper ][ project ][ talk ]
Talk
Volumetric Graph Convolutional Network (VGCN)
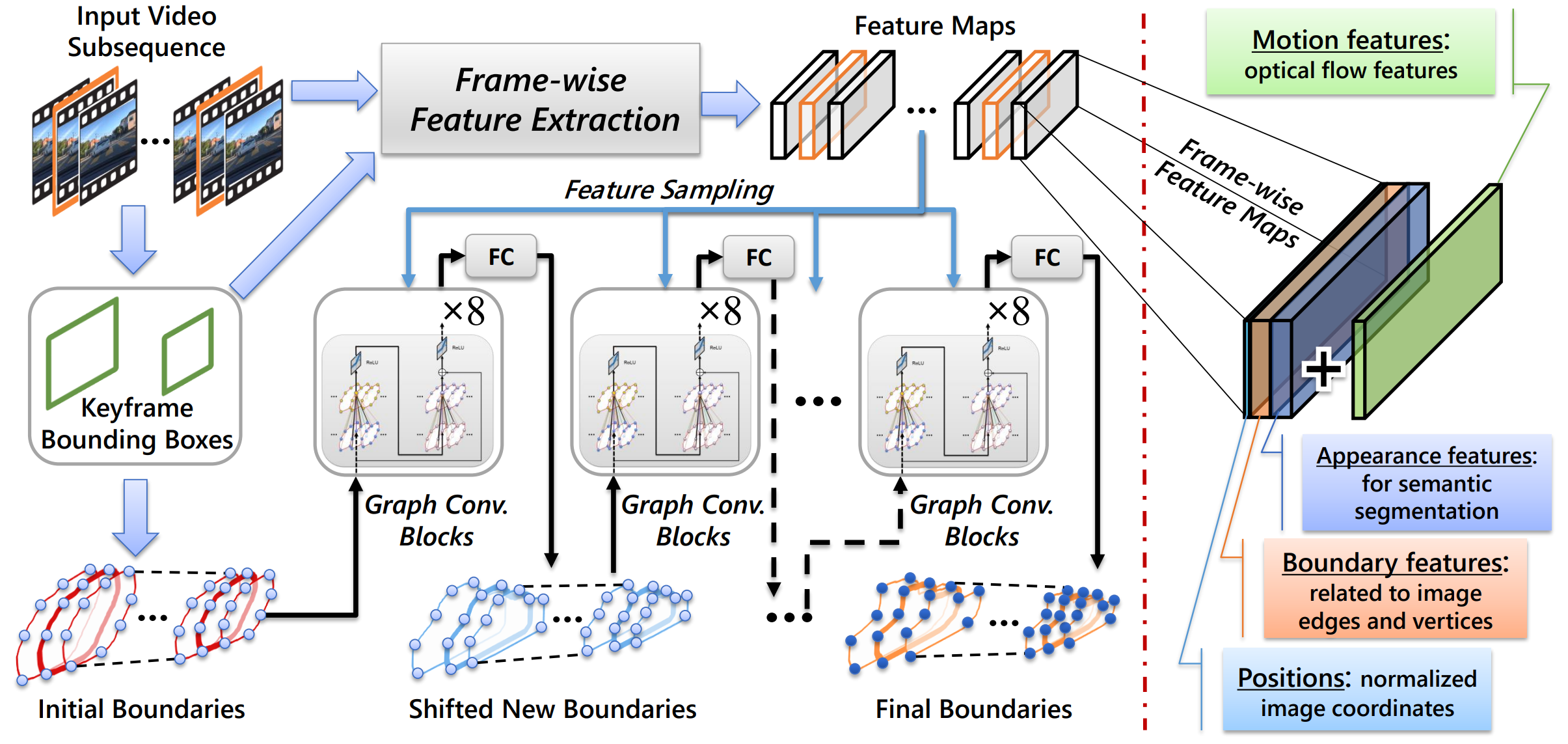
Given an input video sub-sequence bounded by two chosen keyframes, the annotator-provided keyframe bounding boxes are used to crop the video frames, normalize them, and extract frame-wise feature maps whose contents are shown on the right. The bounding boxes also help VGCN initialize the locations of its volumetric nodes that correspond to the keypoints of desired boundaries of all video frames. Then the model samples features from the feature maps according to the node (i.e., boundary keypoint) locations, and such sampled features are fed into a group of graph convolutional blocks (eight of them in our implementation) for information integration and propagation. A fully-connected (FC) layer is adopted to map the updated features of each node to its predicted location shifts. After the actual shifting of node locations, another round of feature sampling and graph convolutions can be applied to predict a new round of location shifts. This process can be iterated several times to ensure an accurate fit to the actual region boundaries.
Graph Convolutional Block
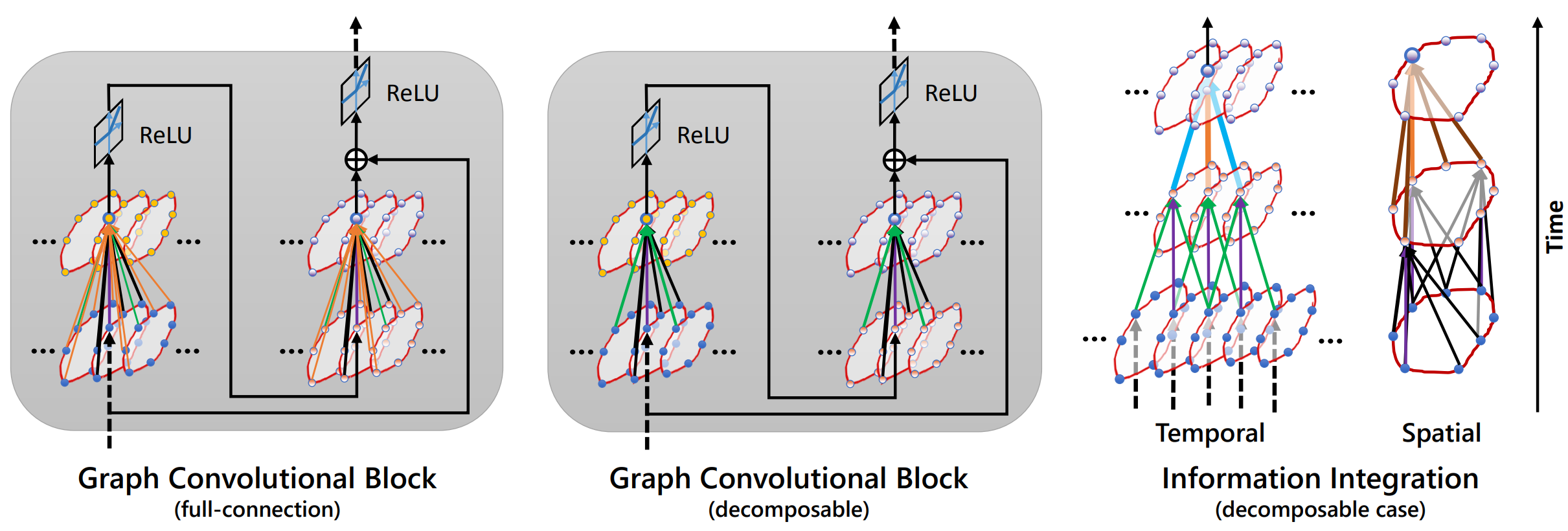
The graph convolutional block of VGCN. Both full local connection and decomposable local connection are illustrated. The right subfigure shows how the information from graph nodes (boundary keypoints) is integrated spatially and temporally, using the decomposable model as an example. For decomposable local connection, spatially, it integrates the information of four adjacent neighbors; temporally, it aggregates the points with the same id number in adjacent frames. For full connection graph structure, based on decomposable local connection, we add eight extra points in information aggregation which are eight adjacent points of the two temporal neighbors. The convolution can be viewed as spatio-temporal information integration and propagation. When several blocks are applied, each node can get information from a significantly large area of the video.
Results
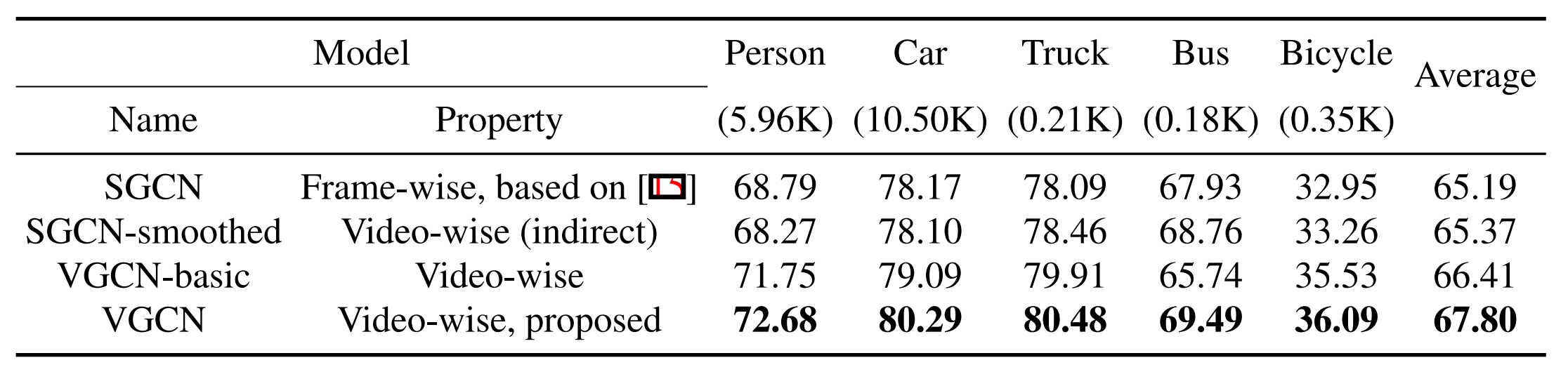
Instead of video-wise joint boundary inference, one may simply apply a frame-wise model (here we choose Curve-GCN as it is the state-of-the-art and also the most elegant model) to each video frame with either the provided bounding box (in case of keyframes) or some interpolated bounding box (for an intermediate frame). We refer to this model as Spatial Graph Convolutional Network (SGCN), as it is also based on GCN and only does the graph convolutions spatially. Despite its simplicity, SGCN has a natural limitation of omitting the temporal relationships among successive video frames. To overcome it, one may also think about simply smoothing the results of SGCN on successive video frames using a B-spline function, so that the overall model can be made indirectly video-wise. Such a simple solution is named ‘SGCN-smoothed’. However, we believe that a direct modeling of temporal relationships in the model like the proposed VGCN is necessary and superior. To better show the performance difference of direct spatio-temporal modeling and indirect result smoothing, we also test a simplified version of VGCN named ‘VGCN-basic’, by only keeping the minimal temporal connection and excluding the motion features. Note that for a fair comparison, all the compared models are trained with the same data which only have ground-truths on the sparse key frames. On the Synthia dataset, our VGCN gets the best results. It surpasses both SGCN and VGCN-basic. We find that the smoothing operation actually hurts the performance, indicating that simple temporal smoothing is not a good choice.
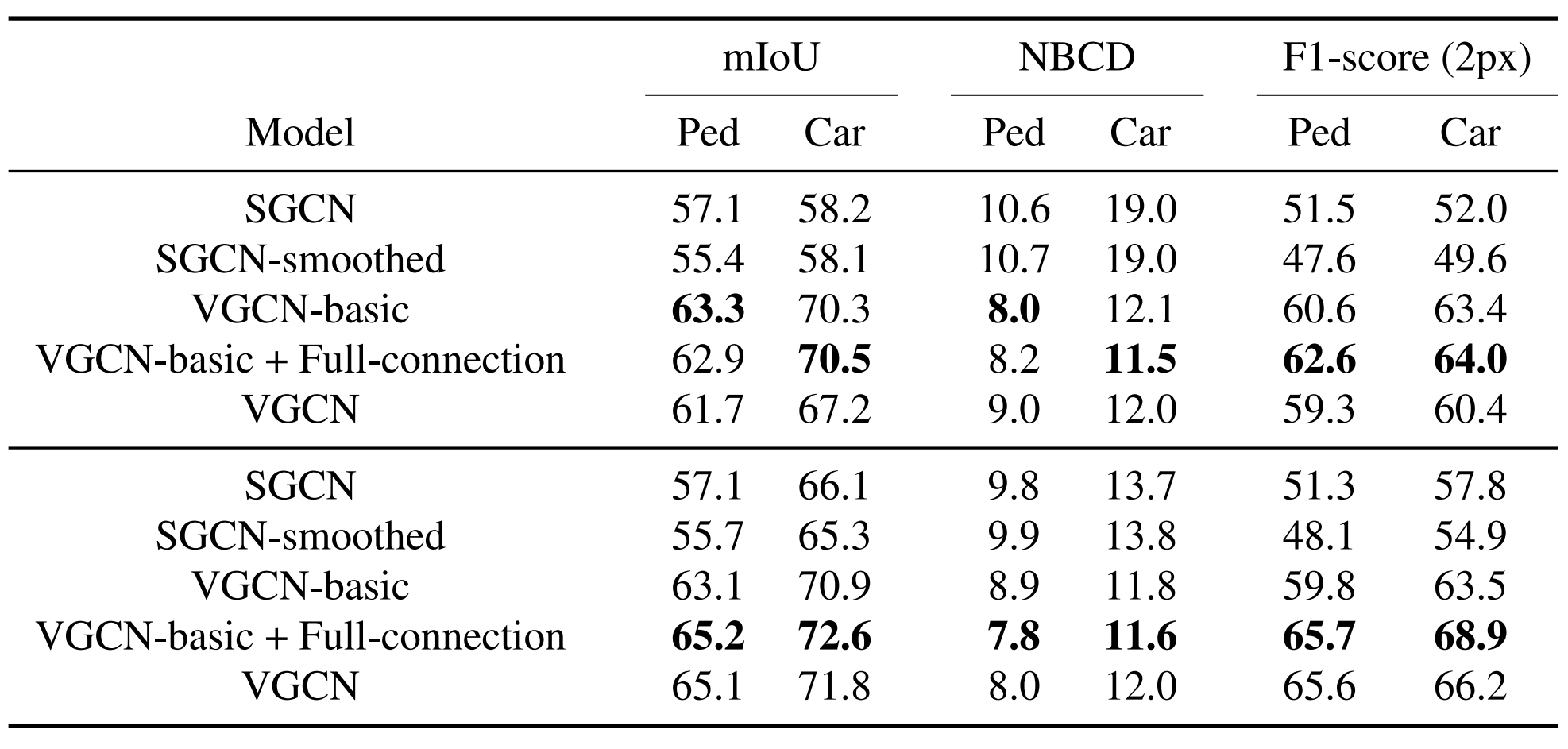
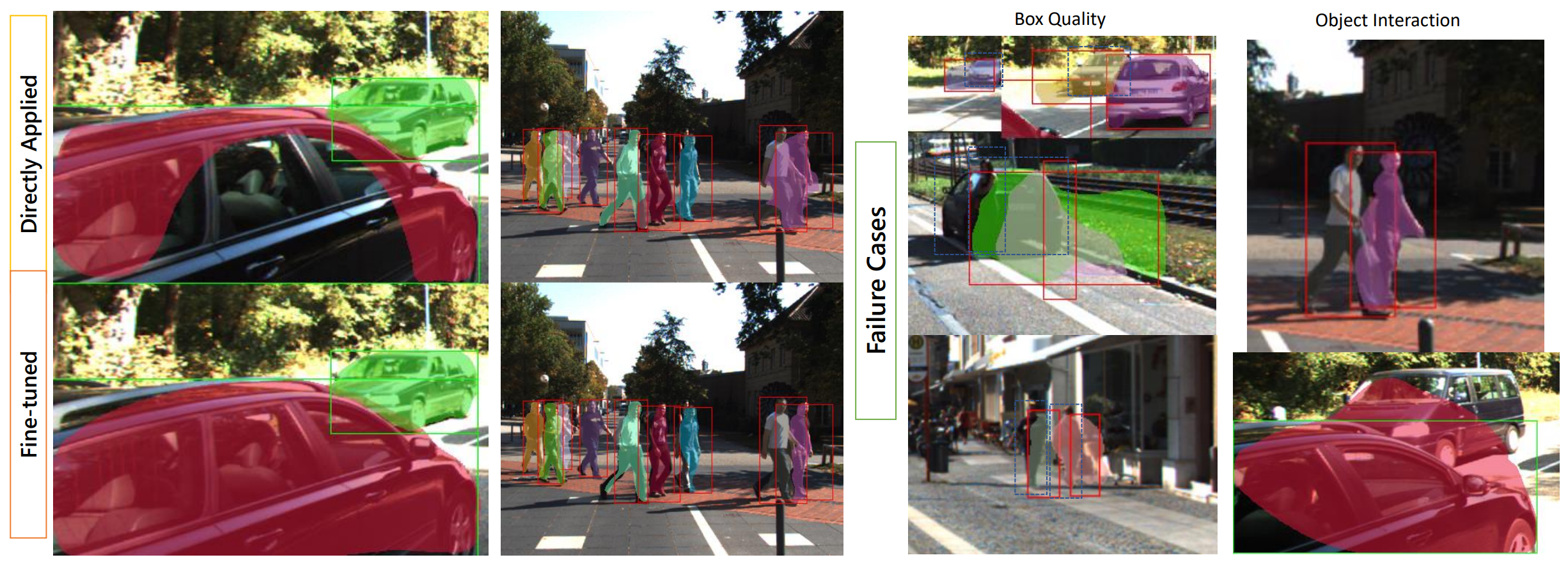
Since the GCN-based models have no assumption on the data, they can be applied to arbitrary video data. We conduct two types of experiments to validate the generalizability of VGCN, in comparison with its competitors. One is about directly applying models trained on Synthia to the test set of KITTI MOTS. The results are shown in the upper part of the figure. The other is fine-tuning the pre-trained model (trained on Synthia) on the small training set of KITTI MOTS and then testing the fine-tuned models on its test set. The results for this are shown in the lower part of the figure. We fixed the feature extraction part, the FC layers of VGCN and its graph convolution layers, and just tuned the network for feature aggregation. VGCN models all outperform SGCN-based ones by large margins. We can see that motion features hurt VGCN in both direct application and fine-tuning, but full-connection significantly helps. Fine-tuning doesn’t benefit GCN-basic, but it significantly enhances VGCN when full-connection is adopted. These findings indicate that the major difference between synthetic data and real data is probably on the motion patterns, instead of adapting motion features which may be hard, fine-tuning the full temporal connections is more effective
Examples on how fine-tuning benefits VGCN and two representative failure cases: undesirable region due to badly interpolated boxes and extra part caused by object interaction.
Our model is trained with a key-frame interval of 10 and tested with intervals 4, 10 and 18, for the ablation study on the sparsity of manual annotations. It shows the performance variation of the compared models on KITTI-MOTS, with different K values. The results are averaged over ‘Ped’ and ‘car’. All the models perform worse when K is increased. VGCN models always outperform SGCN.