Multistable Shape from Shading Emerges from Patch Diffusion
Xinran Nicole Han1, Todd Zickler1, and Ko Nishino2 1Harvard University 2Kyoto University
Models for monocular shape reconstruction of surfaces with diffuse reflection-shape from shading-ought to produce distributions of outputs, because there are fundamental mathematical ambiguities of both continuous (e.g., bas-relief) and discrete (e.g., convex/concave) varieties which are also experienced by humans. Yet, the outputs of current models are limited to point estimates or tight distributions around single modes, which prevent them from capturing these effects. We introduce a model that reconstructs a multimodal distribution of shapes from a single shading image, which aligns with the human experience of multistable perception. We train a small denoising diffusion process to generate surface normal fields from 16 by 16 patches of synthetic images of everyday 3D objects. We deploy this model patch-wise at multiple scales, with guidance from inter-patch shape consistency constraints. Despite its relatively small parameter count and predominantly bottom-up structure, we show that multistable shape explanations emerge from this model for ambiguous test images that humans experience as being multistable. At the same time, the model produces veridical shape estimates for object-like images that include distinctive occluding contours and appear less ambiguous. This may inspire new architectures for stochastic 3D shape perception that are more efficient and better aligned with human experience.
Multistable Shape from Shading Emerges from Patch Diffusion
XN. Han, T. Zickler, and K. Nishino,
in Advances in Neural Information Processing Systems NeurIPS’24. [spotlight]
[ arXiv ][ project ][ code/data ]
Model
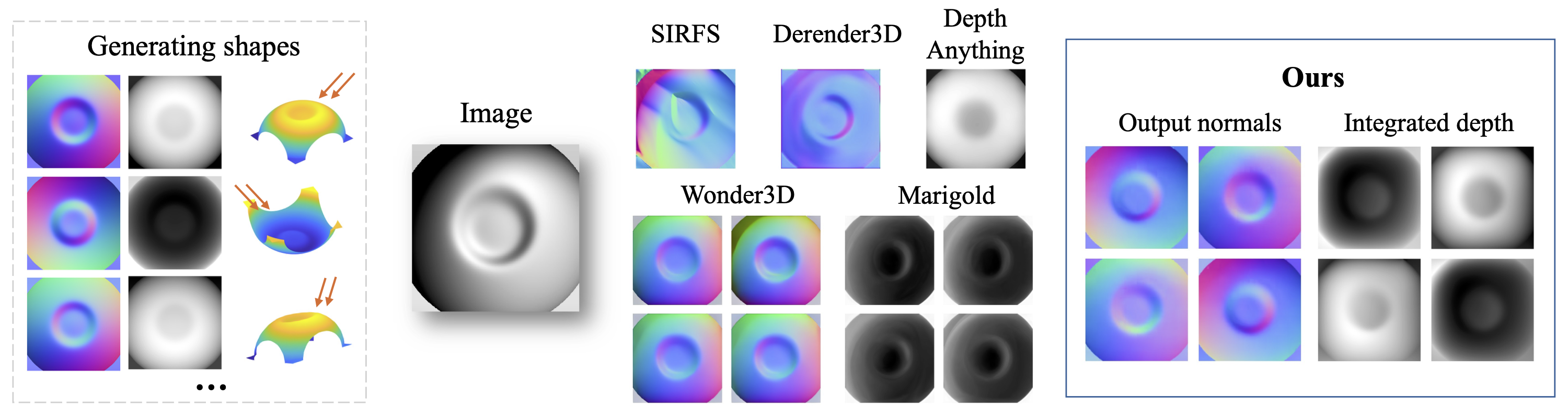
The main challenge of shape from shading comes from the many levels of inherent ambiguity. In the image above, many shapes (left) can explain the same image (middle) under different lighting, including flattened and tilted versions and convex/concave flips. The concave/convex flip in this example is also perceived by humans, often aided by rotating the image clockwise by 90 degrees. Previous methods for inferring surface normals (SIRFS, Derender3D, Wonder3D) or depth (Marigold, Depth Anything) produce a single shape estimate or a unimodal distribution. Our model produces a multimodal distribution that matches the perceived flip.
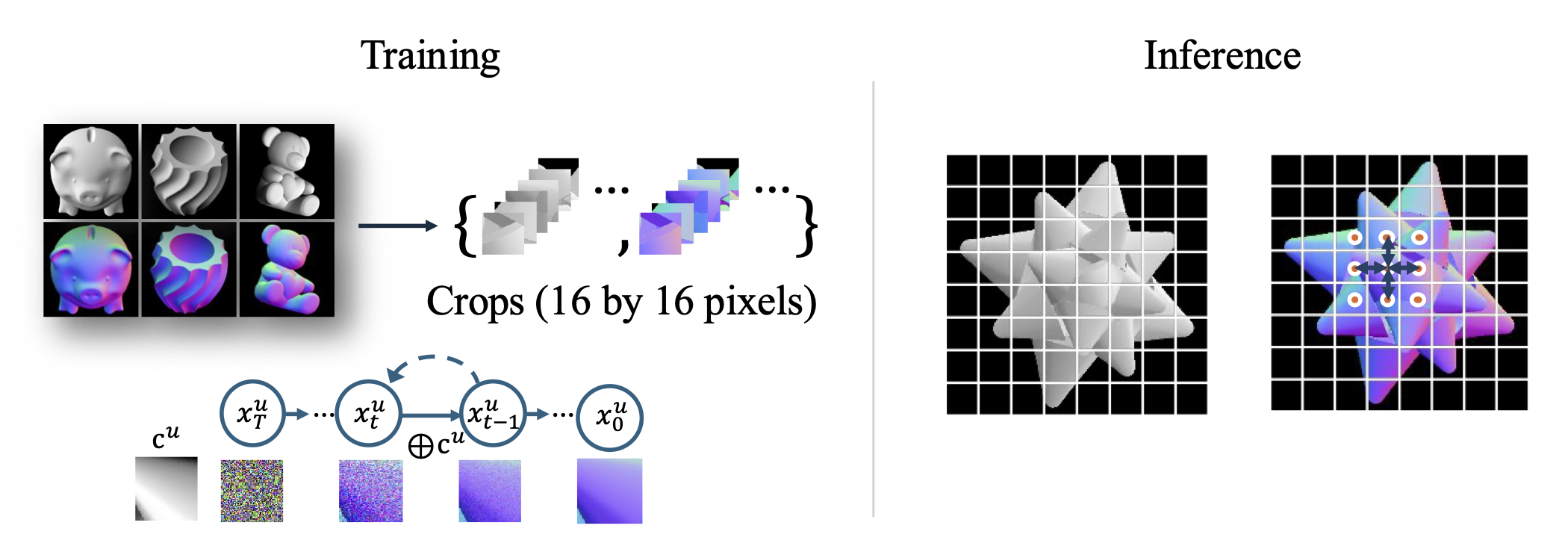
Our model is trained using images of familiar object-like shapes and has no prior experience with the ambiguous images that we use for testing. It is built on a small conditional diffusion process that is pre-trained to predict surface normals from 16 by 16 pixel image patches. During inference time, we formulate the global image and normal field as an undirected, four-connected graph, where each patch is a node, and there are edges between pairs of patches that are horizontally or vertically adjacent. When this pre-trained patch diffusion process is applied in a non-overlapping manner with simple inter-patch shape consistency constraints, our model coordinates those patches in the sampling process and turns out to capture global ambiguities that are experienced by humans.
The figure above demonstrates the importance of the three key components of our model. The left of the figure shows that when each patch is reconstructed independently, the resulting normals are inconsistent, because each patch may choose a different concave/convex mode as well as its various flattenings and tiltings. When spatial consistency guidance is applied at one scale, the global field is more consistent but suffers from discontinuous seams due to poor local minima. With multiscale sampling the seams improve, but separate bump/dent regions can still choose different modes without being consistent with any single dominant light direction. Finally, when lighting consistency is added, the output fields become more concentrated around two global modes—one that is globally convex (lit primarily from below) and another that is globally concave (lit primarily from above).
Results
Conditioning on images and shapes that we intentionally designed to be ambiguous, we draw 100 samples from our model and another method (Wonder3D) and project the results to the 2D plane using t-SNE. The scatter plots show that our model outputs a multimodal distribution that is also close to the possible ground truths, while the other model’s output distribution covers only one mode or is close to a plane. These differences in coverage and accuracy are also apparent in terms of Wasserstein distance.
We also captured photos of real-world objects that induce multistable perceptions for human observers. We find that our model’s multimodality is qualitatively well aligned with perceptual multistability.