Correspondences of the Third Kind Camera Pose Estimation from Object Reflection
Kohei Yamashita1, Vincent Lepetit2, and Ko Nishino1 1Kyoto University 2Ecole des Ponts ParisTech
Computer vision has long relied on two kinds of correspondences: pixel correspondences in images and 3D correspondences on object surfaces. Is there another kind, and if there is, what can they do for us? In this paper, we introduce correspondences of the third kind we call reflection correspondences and show that they can help estimate camera pose by just looking at objects without relying on the background. Reflection correspondences are point correspondences in the reflected world, i.e., the scene reflected by the object surface. The object geometry and reflectance alters the scene geometrically and radiometrically, respectively, causing incorrect pixel correspondences. Geometry recovered from each image is also hampered by distortions, namely generalized bas-relief ambiguity, leading to erroneous 3D correspondences. We show that reflection correspondences can resolve the ambiguities arising from these distortions. We introduce a neural correspondence estimator and a RANSAC algorithm that fully leverages all three kinds of correspondences for robust and accurate joint camera pose and object shape estimation just from the object appearance. The method expands the horizon of numerous downstream tasks, including camera pose estimation for appearance modeling (e.g., NeRF) and motion estimation of reflective objects (e.g., cars on the road), to name a few, as it relieves the requirement of overlapping background.
Correspondences of the Third Kind: Camera Pose Estimation from Object Reflection
K. Yamashita, V. Lepetit, and K. Nishino,
in Proc. of European Conference on Computer Vision ECCV’24, Oct., 2024. [oral]
[ paper ][ supp. PDF ][ project ][ code/data ]
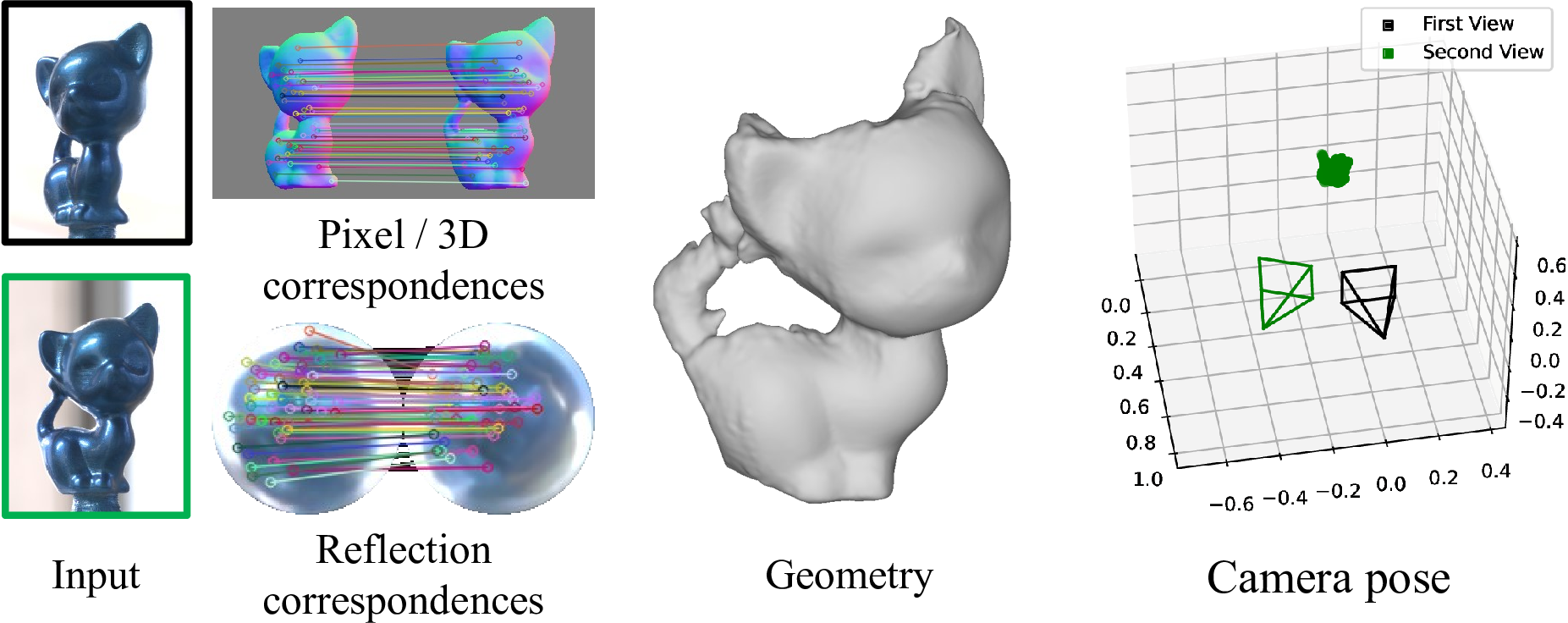
Overview
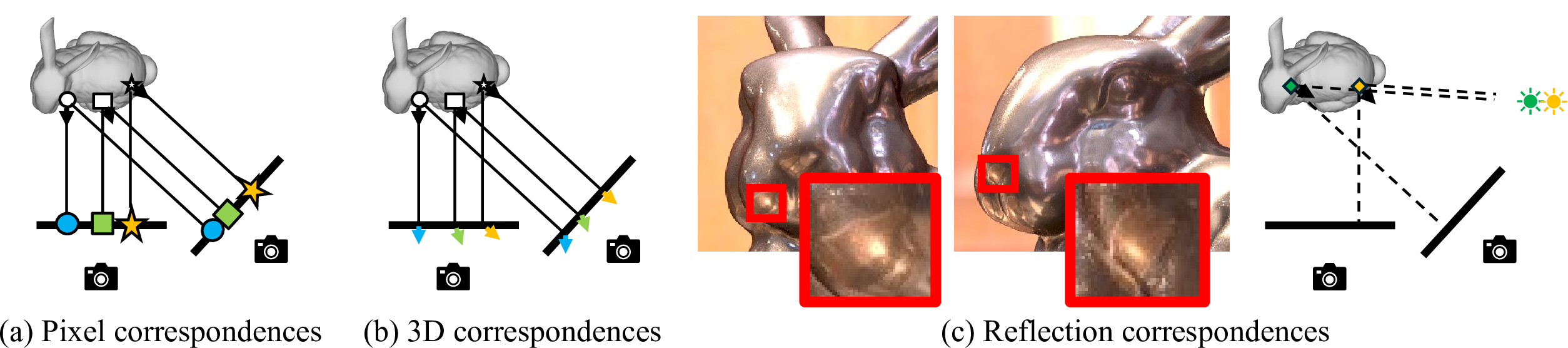
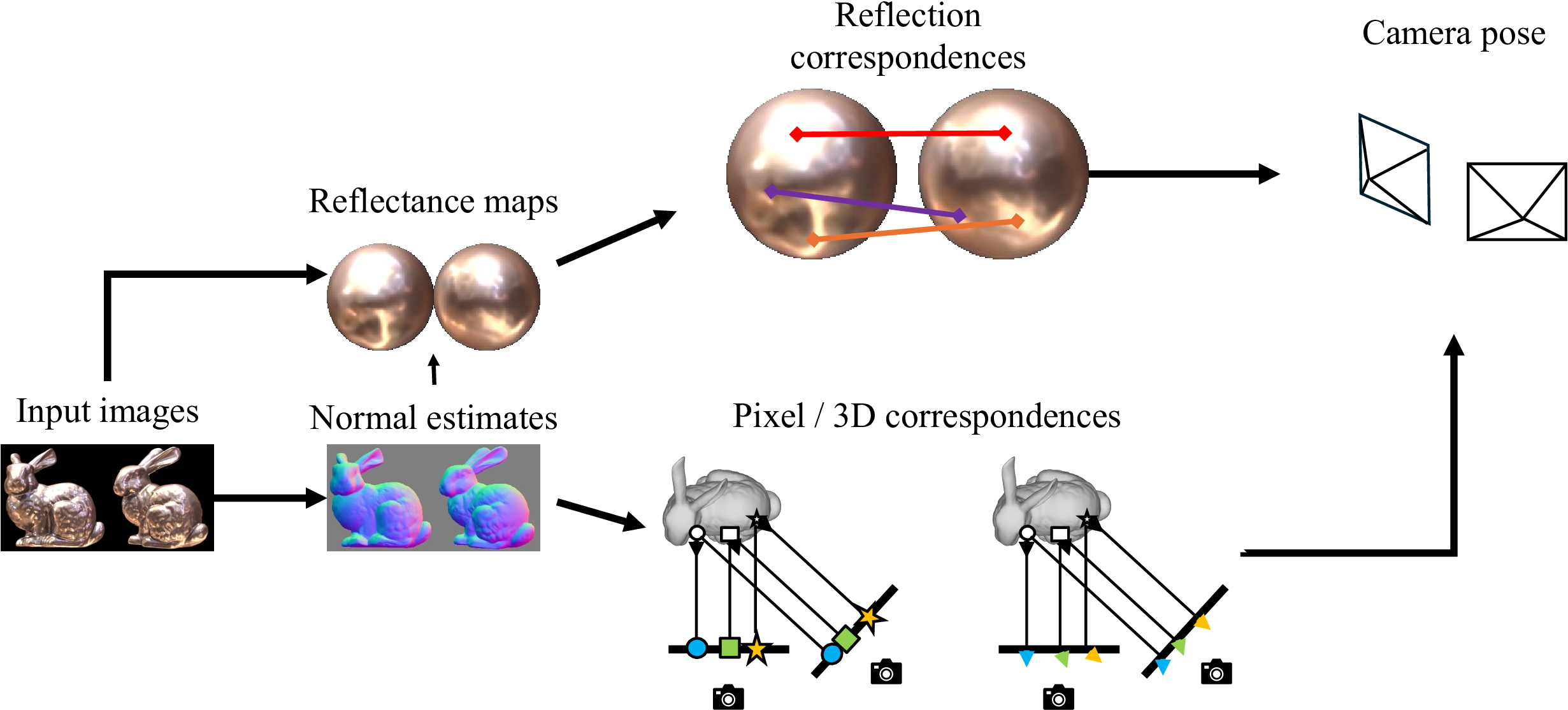
We leverage two kinds of conventional correspondences and a novel kind of correspondences we call reflection correspondences. (a) Pixel correspondences link corresponding locations in the two images on the object surface: the two matched points are the reprojections of the same physical 3D point in the two images. (b) 3D correspondences link corresponding normals in the two images on the object surface. Note that for each pixel correspondence, we also have a 3D correspondence if we know the normals at the matched image locations. The difference is that for the pixel correspondence, we exploit the pixel coordinates themselves, while in the case of the 3D correspondence, we exploit the normals. (c) Reflection correspondences match image locations where light rays mirror-reflected by the object surface come from the same direction in the two images.
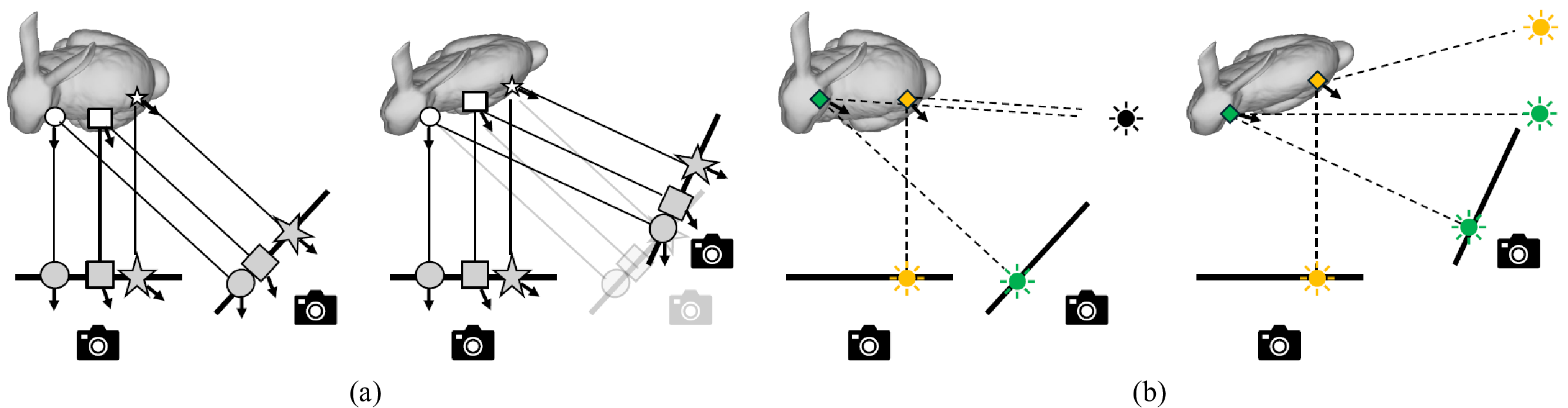
(a) Multiple possible solutions obtained from the conventional correspondences. Due to the generalized bas-relief ambiguity in single-view surface normal recovery and the fundamental difficulty in structure-from-motion, we cannot obtain a unique solution for the relative rotation from pixel and 3D correspondences when the cameras are orthographic (e.g., distant from the object). (b) Reflection correspondences, i.e., correspondences regarding the incident directions for specular reflections, enable us to distinguish the correct relative rotation (left) from the other possible solutions (right).
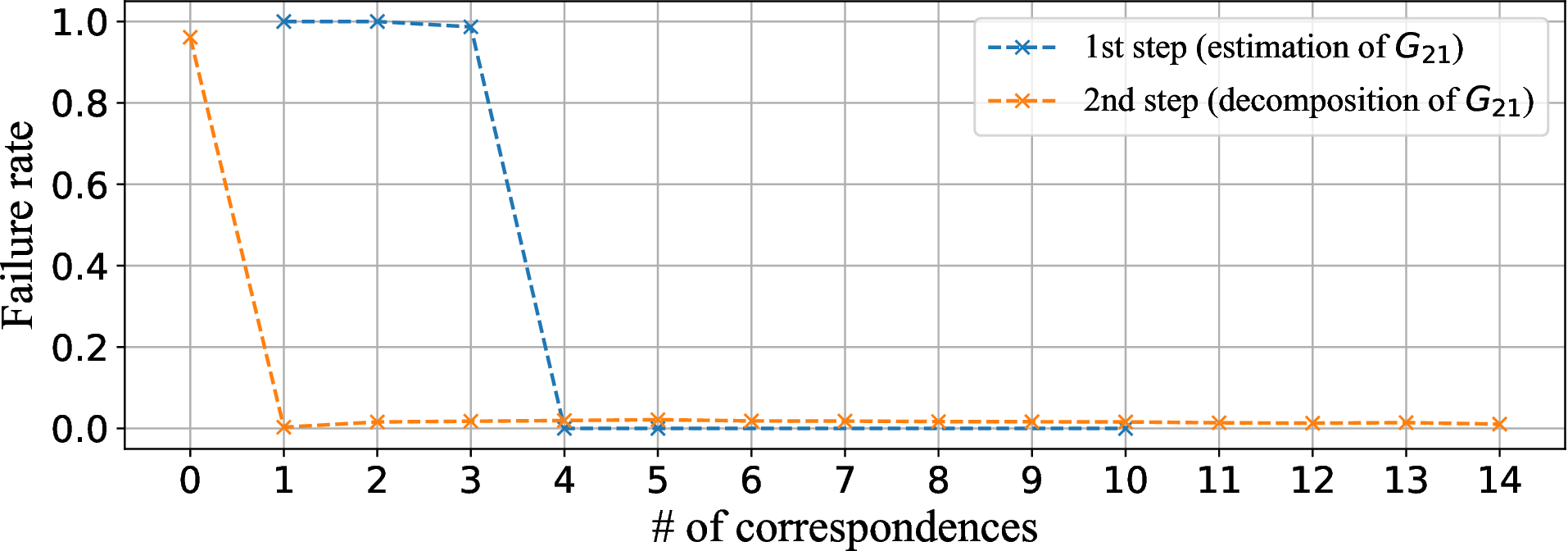
By an empirical analysis on synthetic correspondences, we found that four conventional correspondences are needed to solve the relative camera pose up to the fundamental ambiguity (blue line). More formally, we require four conventional correspondences to obtain a combined transformation (G21) of two generalized bas-relief transformations for the views and the relative rotation. We also found that one reflection correspondence is sufficient to resolve the remaining ambiguity and enables us to decompose the combined transformation (orange line). In practice, we first solve the combined transformation using conventional correspondences (first step) and then decompose it using reflection correspondences (second step).
Detecting reflection correspondences directly from images is, however, extremely challenging as surface reflection depends not only on the surrounding illumination but also on the surface geometry. We avoid this problem by recovering camera-view reflectance maps, view-dependent mappings from a surface normal to the surface radiance which are determined only by the surface reflectance and the surrounding illumination environment. We introduce a new neural feature extractor for establishing 3D and reflection correspondences robust to the inherent distortions primarily caused by the bas-relief ambiguity with effective data augmentation.
Results
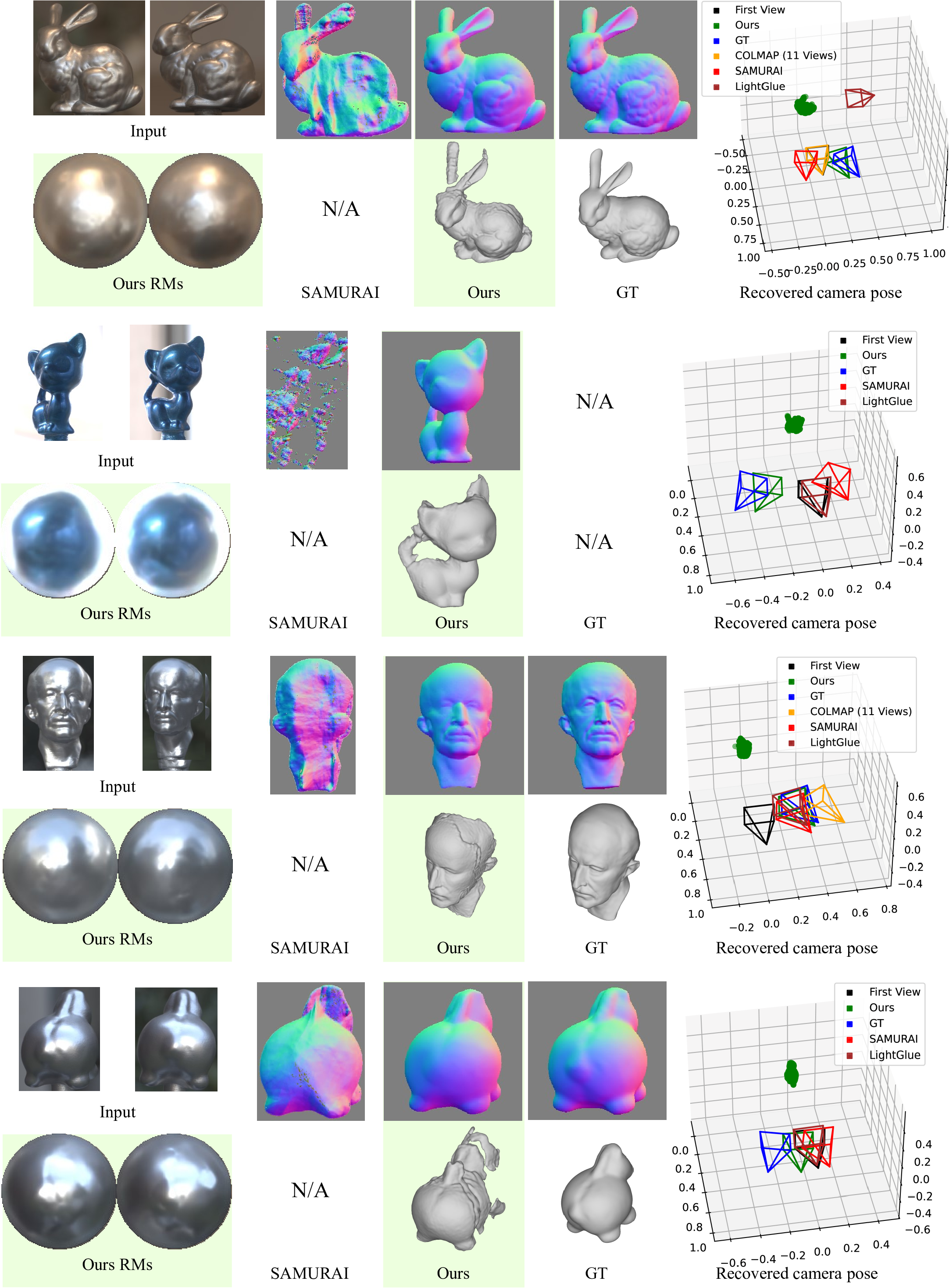
Reflectance maps (RMs), normal maps, surface geometry, and relative camera poses recovered from real image pairs in the nLMVS-Real dataset and on an image pair captured by ourselves. As SAMURAI failed to extract a 3D mesh model from their volumetric geometry representation, we only show a normal map for SAMURAI. In contrast to these existing methods which fail on these challenging inputs, our method successfully recovers plausible camera poses, surface geometry, and reflectance maps.
Correspondences detected from real image pairs in the nLMVS-Real dataset and on an image pair captured by ourselves. Visual inspection shows that they match semantically correct surface and reflectance map points.
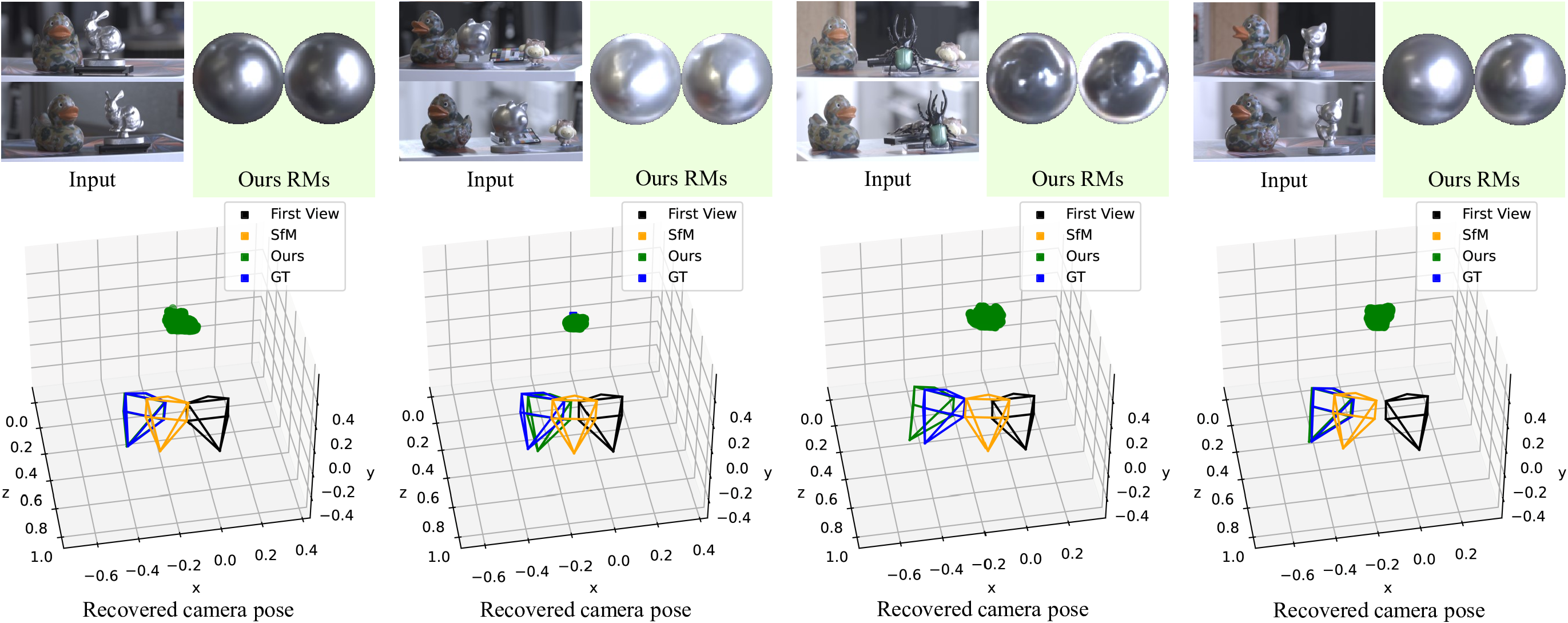
We can also leverage our method to estimate camera poses from sparse images capturing scenes consisting of both textured and textureless, non-Lambertian objects often found in the real world. In such a setting, the pixel correspondences can come from the textured object, and the reflection correspondences from the textureless object. The results show that our camera pose estimation result (green) is almost identical to the ground truth (blue) compared to a baseline structure-from-motion method (yellow). This demonstrates the effectiveness of our method even in scenes consisting of multiple different types of objects.
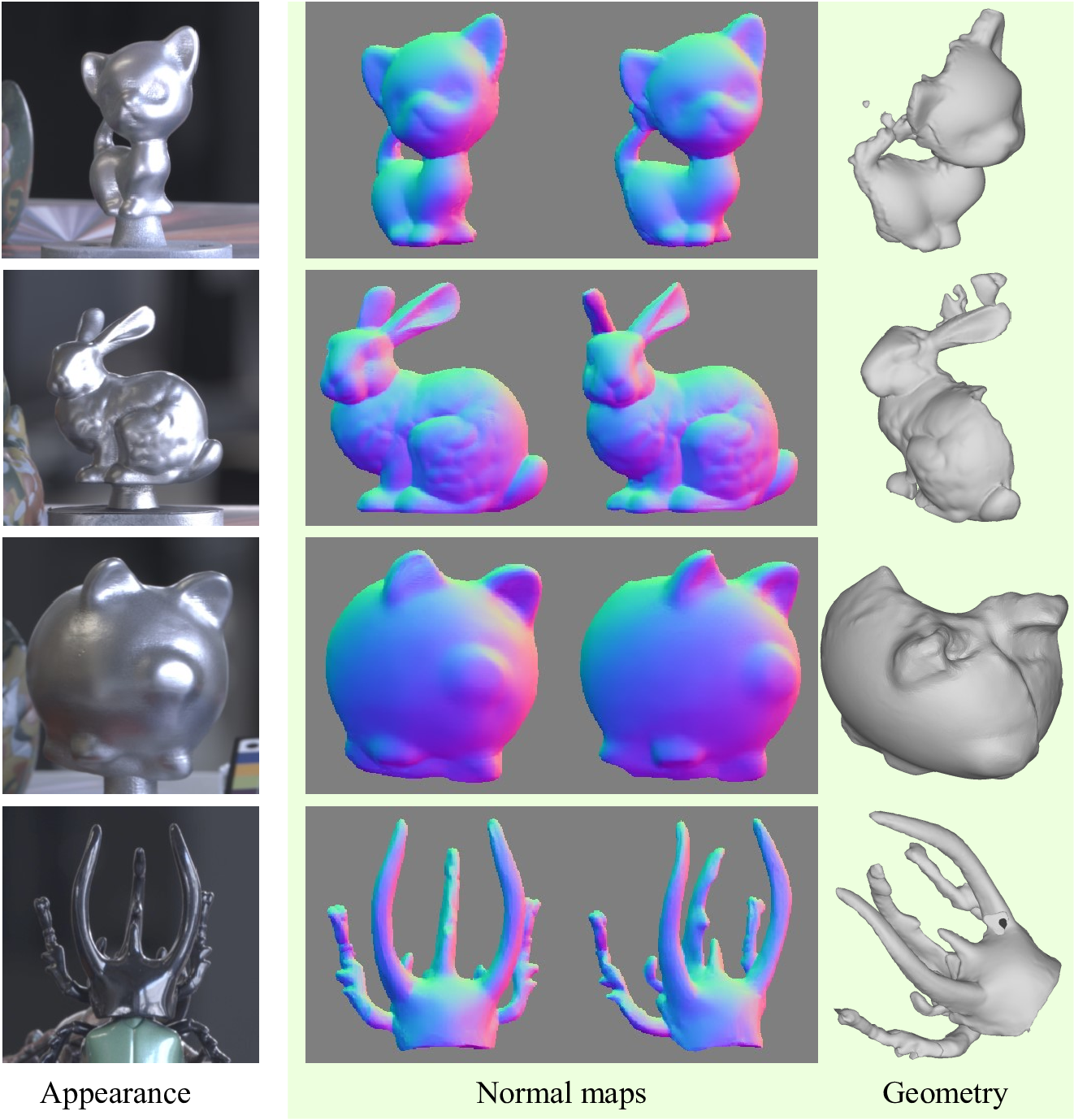
Normal maps and surface geometry of textureless, non-Lambertian objects recovered from the two-view real images of scenes with different objects. The recovered geometry is qualitatively plausible for the captured objects.